北航计组-P5课下
前言
P5的工程量真的很大,建议不要盲目开始,上来就敲代码,而是先规划好自己的设计,确定架构,命名规范,这样搭建起来就容易多了,在开始P5之前,你得完成以下工作
- 阅读完P5教程
- 阅读理解完相应的流水线CPU设计的PPT或者黑书的相关章节
- 多看几位学长的博客,确定好自己的架构
- 完成草图设计,或者直接用别人的或者书上的,但一定要清楚自己的整体设计
- 可能老师PPT上的设计图并不完整,没有必要的转发线路,自己注意辨别
- 如果你懒得自己设计或者找正确的设计图,下面这份我自己的设计图或许能对你有所帮助
- 在阅读下文之前,你得至少完成上文提到的必备工作的前两点
设计要点
下面是我用logisim设计的一份架构草图,直接在P3上面改的,没那么美观,有些细节也没有,大家看清楚结构和逻辑就好
我的设计是分布式译码,但是需要将D级产生的Tnew信号流水至E M级,通过AT法判断冲突
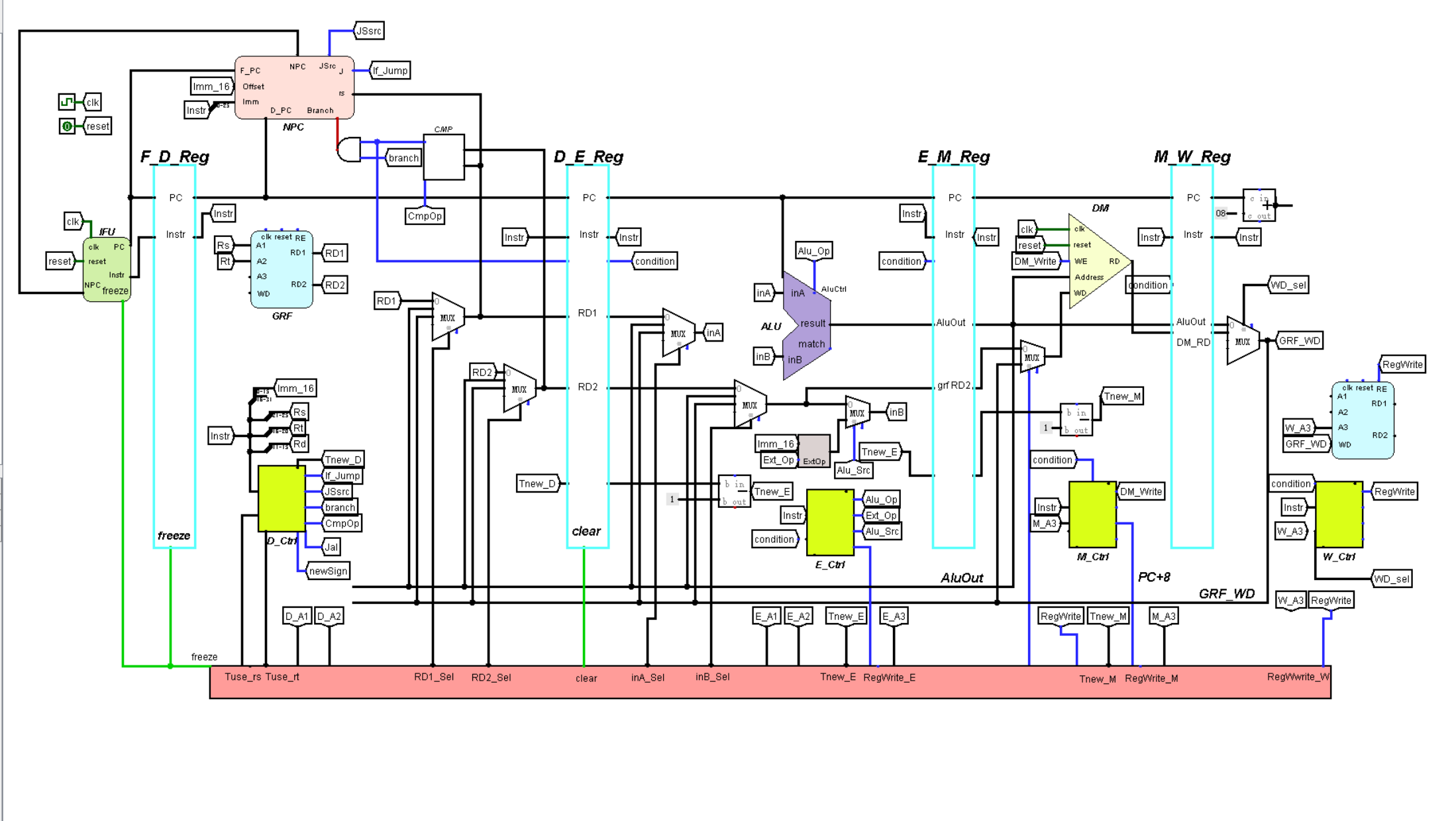
在P5我们将指令的执行分为了五个阶段
- F级取指令
- D级取寄存器的值,进行跳转判断,并且根据判断结果决定NPC
- E级进行ALU运算
- M级对DM进行存取
- W级写寄存器
每个阶段的一些状态信息和数据都通过流水线寄存器传递给下一个阶段,从而继续执行该指令
那么,我们需要在W级才能写入寄存器,但此时在D E M级的指令又需要寄存器的值来进行一系列操作,如果是同一个寄存器,那么就发生了数据冲突,怎么解决呢?就是采用转发或者阻塞
转发
试想一下下面这一段代码
1 | |
lw 在D级时从GRF中取出4号寄存器的值,但是这时候add指令在E级,4号寄存器的值还未更新,我们取到的并不是一个正确的寄存器的值,那怎么办呢?我们不妨想想,对于lw指令,我们在D级真的需要4号寄存器的正确值吗?并不需要,因为在E级lw指令才会参与运算,所以我们真正需要4号寄存器的值是在E级,也就是说Tnew_rs = 1,此时add指令在M级,虽然此时我们lw指令得到的值并非正确,但真正正确的值已经产生了,就在AluOut里面,那么此时我们将M级AluOut的值给ALU的第一个输入inA,这样inA的值就得到了矫正
上面就是转发的分析过程,这组数据还有不少其他的转发情况,请自行分析清楚
同时,由于beq指令的判断在D级,我们此时必须要得到正确的寄存器的值,也就是Tuse为0
总的来看,转发线路至少要有这么几条
M到D,W到D, M到E,W到E,W到M(有老师的PPT里没有这个线路)
W到D其实就是所谓的内部转发,但其实把GRF看成两个部件的话,也就没有内部转发这一说了
阻塞
上面的例子中,我们要得到正确寄存器的值的时候,这个值已经产生了,就在某个流水线寄存器里面,我们可以直接转发,但是如果这个值没有产生呢?
比如说add后面跟一个beq指令,beq在D级就需要得到正确寄存器的值,但此时E级的add还没有正确的值(课程组要求必须从流水线寄存器后面转发,所以不能直接E级ALU的结果)
很遗憾,我们这时候只能够暂停后面的流水线,直到正确的寄存器的值产生,这就是阻塞
具体的说,我们只需要将DE级流水线寄存器的指令设为0,同时保持IFU里的PC不变,F级的指令不变,FD流水线寄存器不变,这样等效于在add和beq之间插入了一个nop指令,阻塞之后M级就可以向D级转发正确的数据了
综合
T信号
Tuse:指令进入 D 级后,其后的某个功能部件再经过多少时钟周期就必须要使用寄存器值。对于有两个操作数的指令,其每个操作数的 Tuse 值可能不等(如 store 型指令 rs、rt 的 Tuse 分别为 1 和 2 )。- Tnew:位于 E 级及其后各级的指令,再经过多少周期就能够产生要写入寄存器的结果。在我们目前的 CPU 中,W 级的指令Tnew 恒为 0;对于同一条指令,Tnew_next = max(Tnew_now - 1, 0),本表格中我们分析D级的Tnew,并让Tnew随着流水线传递并递减,x表示不需要使用寄存器,代码中设置为3即可
| 指令分类 | Tuse_rs | Tuse_rt | Tnew |
|---|---|---|---|
| calc_R | 1 | 1 | 2 |
| calc_I | 1 | x | 2 |
| load | 1 | x | 3 |
| store | 1 | 2 | 0 |
| branch | 0 | 0 | 0 |
| Jal | x | x | 2 |
| Jr | 0 | x | 0 |
冲突控制单元CU
Tuse < Tnew时必须要阻塞Freeze,Tuse>Tnew时转发Forward即可
Tuse/Tnew | Tnew_E | Tnew_E | Tnew_E | Tnew_M | Tnew_M | Tnew_W |
|---|---|---|---|---|---|---|
Tuse | 2 | 1 | 0 | 1 | 0 | 0 |
0 | Freeze | Freeze | Forward | Freeze | Forward | Forward |
1 | Freeze | Forward | Forward | Forward | Forward | Forward |
2 | Forward |
因此我们需要设置好每条指令的Tnew和Tuse,再根据RegWrite等信号以及寄存器编号是否相等来判断转发或者阻塞逻辑,当Tnew > Tuse的时候我们就必须要阻塞了
同时必须对0号寄存器进行判断,因为我们无法对0号寄存器进行写入
下面放一个CU模块,也就是冲突处理模块的代码片段
1 | |
解决完转发阻塞后,P5的重大工程已经完成,其他的就照着电路图连线即可,这里想说说jal
jal
乍看jal,似乎D级解码之后我们就知道了PC+8的值,也就是说Tnew为0,但事实如此吗?
在不少人设计中,jal的PC是流水到W级才写入寄存器的,这时候,正确的Tnew应该为3,这样的设计没有问题,但是可能因此造成不必要的阻塞,导致CPU跑不快
我们仔细思考,确确实实D级解码之后我们就知道了PC+8的值,那么我们就需要增加转发线路了,实现E, M, W级PC+8值的转发,这样确实也可以
但我们采用归一化的思想,这样并不好,并不能系统地解决该问题,而是采取了类似特判的形式,我们总得尝试下更优雅的做法吧
我自己摸索出来的一种方法是将E级的PC连到ALU里面,ALU输出PC+8,也就是让jal某种形式上也成了运算类指令,看RTL语言,不也类似么?
这样做的好处就是我们无需对CU模块进行任何修改,只需要像其他运算指令一样将jal的Tnew设置为2,A3设置为31,即可,此时要转发的数据(PC+8)已经在AluOut中了,这样便获得了更好的统一性、归一性
有同学说这样无法实现E到D级的转发啊,仔细想想,对于jal,我们需要E到D的转发么?并不需要
因为考虑延迟槽,当jal在E级时,它的后一条指令也就是D级的指令不会是beq指令,这样的测试数据是非法的,也就是说不会连着跳
那么对于其他的非分支指令,D级并不需要寄存器,这样就不需要转发了
测试
课下的测试数据仅供参考,对了也要自己测一测强一点的数据,避免把课下的bug留到课上,那样就比较难受了
因此,如果对自己的设计没有信心,可以多多构造数据或者用别人的数据狠狠测试,不留bug
对于奆佬,可以按照教程的方式自行构造数据生成器,如果懒得折腾我这里分享一些我的测试数据
测试样例来自于我魔改的学长的数据生成器,同时修复了一些源代码,让生成的数据更合理,冲突更多,测试数据中有j指令,自己加一下,很容易
Mars配置在前面的文章已经说过了,这里别忘了开延时槽噢😁
同时数据较多,建议搭配评测机使用,每年都有奆佬发布评测机,大家多多关注,这里也贴一个lcy同学写的评测机,非常好用,再次感谢❤。相关的源码我已经修改好了,大家只需要修改config.json中的CPU 和MIPS的路径即可,分别对应要测试的CPU文件夹,以及测试数据文件夹,测试结果在tmp文件夹下,我修改为了有不同才会生成.html文件,可以按需求修改源码,然后运行main.py即可(如果刚开始无输出,等一会儿或者多试几次就好了,神奇😆)