李宏毅机器学习-Self-Attention
这是我学习李宏毅机器学习时记录的一些笔记 ,希望能对你有所帮助😊
1. 引言:处理向量集合的挑战
传统神经网络通常处理固定大小的向量输入,但现实应用中输入常为长度可变的向量集合,例如:
- 文本:句子可视为词向量组成的集合
- 语音:音频可转换为帧向量序列
- 图结构:社交网络或分子可视为节点向量集合
Self-attention 能有效处理此类输入,让模型在处理每个向量时动态考虑集合中其他向量的信息
2. Self-Attention 核心思想
处理序列中的向量时,需结合上下文信息。例如判断句子 “I saw a saw” 中第二个 “saw” 的词性时,必须考虑其上下文。
Self-attention 的核心:
- 为序列中每个向量生成输出
- 输出值 = 自身信息 + 与其他向量的关联程度
- 通过注意力分数量化关联性,加权汇总信息
3. Self-Attention 计算步骤
以输入向量序列 $a^1, a^2, a^3, a^4$ 为例:
3.1 生成 Query, Key, Value 向量
对每个输入向量 $a^i$:
- Query($q^i$):当前向量,主动”查询”与其他向量的关联性
- Key($k^i$):其他向量,被 Query “查询”的目标
- **Value($v^i$**):向量本身的信息载体
$$\begin{aligned}
q^i &= W^q a^i \
k^i &= W^k a^i \
v^i &= W^v a^i
\end{aligned}$$
($W^q, W^k, W^v$ 为可学习的权重矩阵)
3.2 计算注意力分数
计算向量 $a^1$ 对 $a^i$ 的注意力分数:
$$\alpha_{1,i} = q^1 \cdot k^i$$
(点积运算衡量向量间的相关性)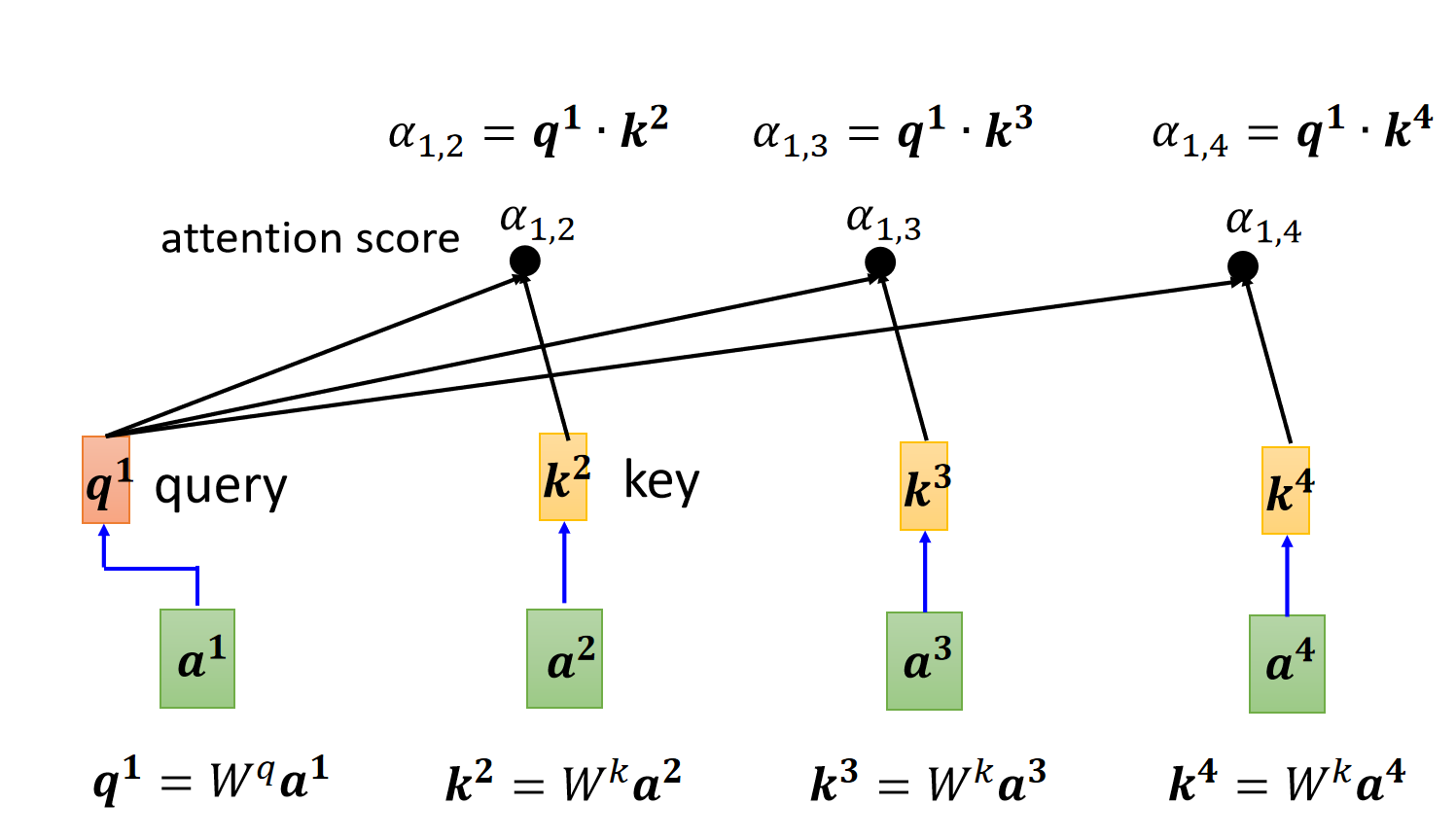
3.3 分数归一化 (Softmax)
使用 Softmax 将分数转化为概率分布:
$$\alpha’{1,i} = \frac{\exp(\alpha{1,i})}{\sum_j \exp(\alpha_{1,j})}$$
(保证 $\sum_i \alpha’_{1,i} = 1$)
3.4 加权求和输出
以归一化分数为权重,对所有 Value 加权求和:
$$b^1 = \sum_i \alpha’_{1,i} v^i$$
(最终输出 $b^1$ 融合了全局相关信息)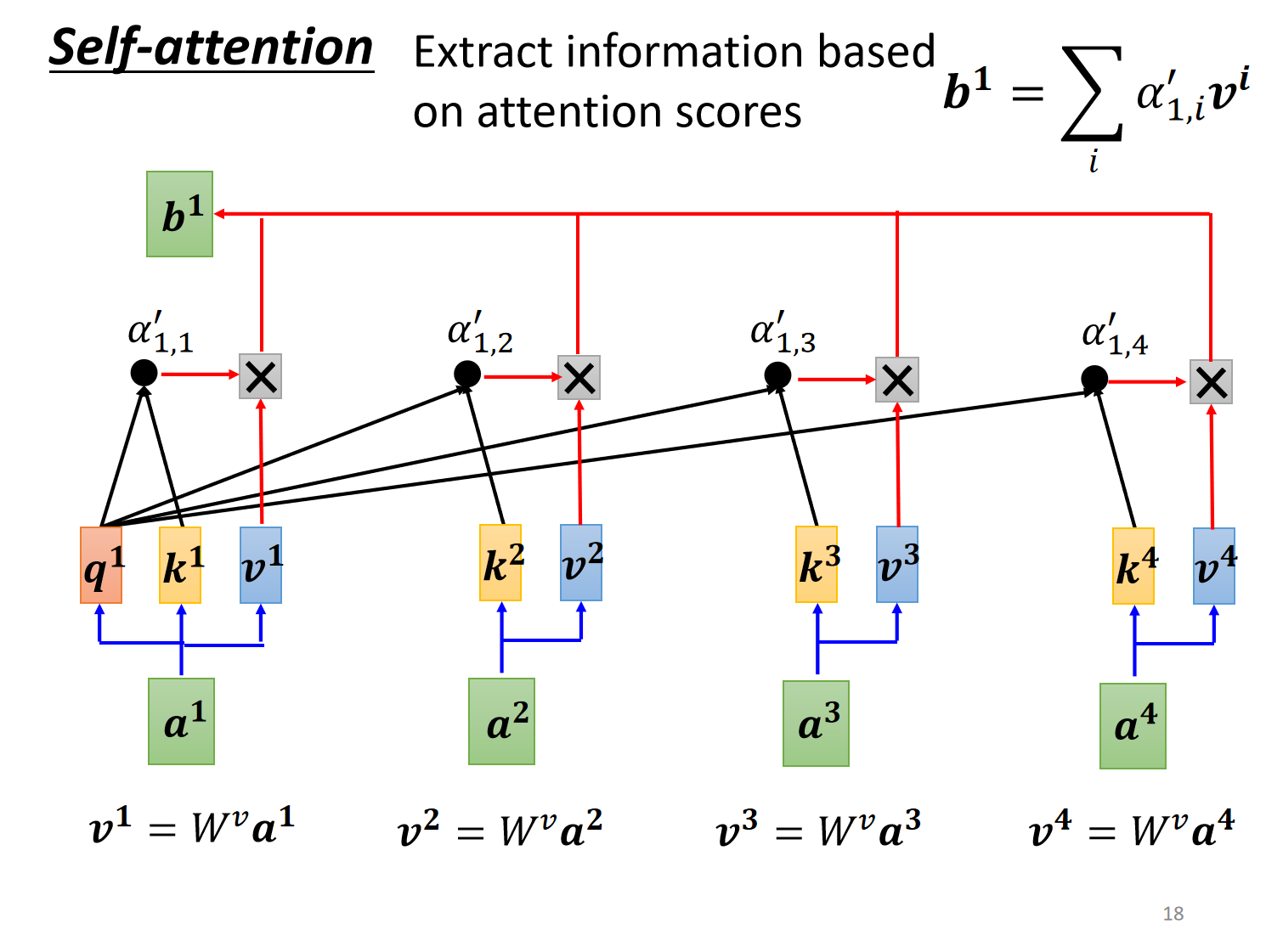
⚡ 优势:对序列中所有向量的计算可并行执行,parallel
4. 矩阵运算实现
通过矩阵运算高效实现上述过程:
| 步骤 | 计算式 | 说明 |
|---|---|---|
| 输入矩阵 | $I = [a^1;a^2;…]$ | 堆叠输入向量 |
| Q/K/V矩阵 | $\begin{aligned} Q &= I W^q \ K &= I W^k \ V &= I W^v \end{aligned}$ | 批量生成向量 |
| 注意力矩阵 | $A = K^T Q$ | 计算所有注意力分数 |
| 归一化 | $A’ = \text{softmax}(A)$ | 行方向归一化 |
| 输出 | $O = V A’$ | 加权求和结果 |
5. 进阶机制
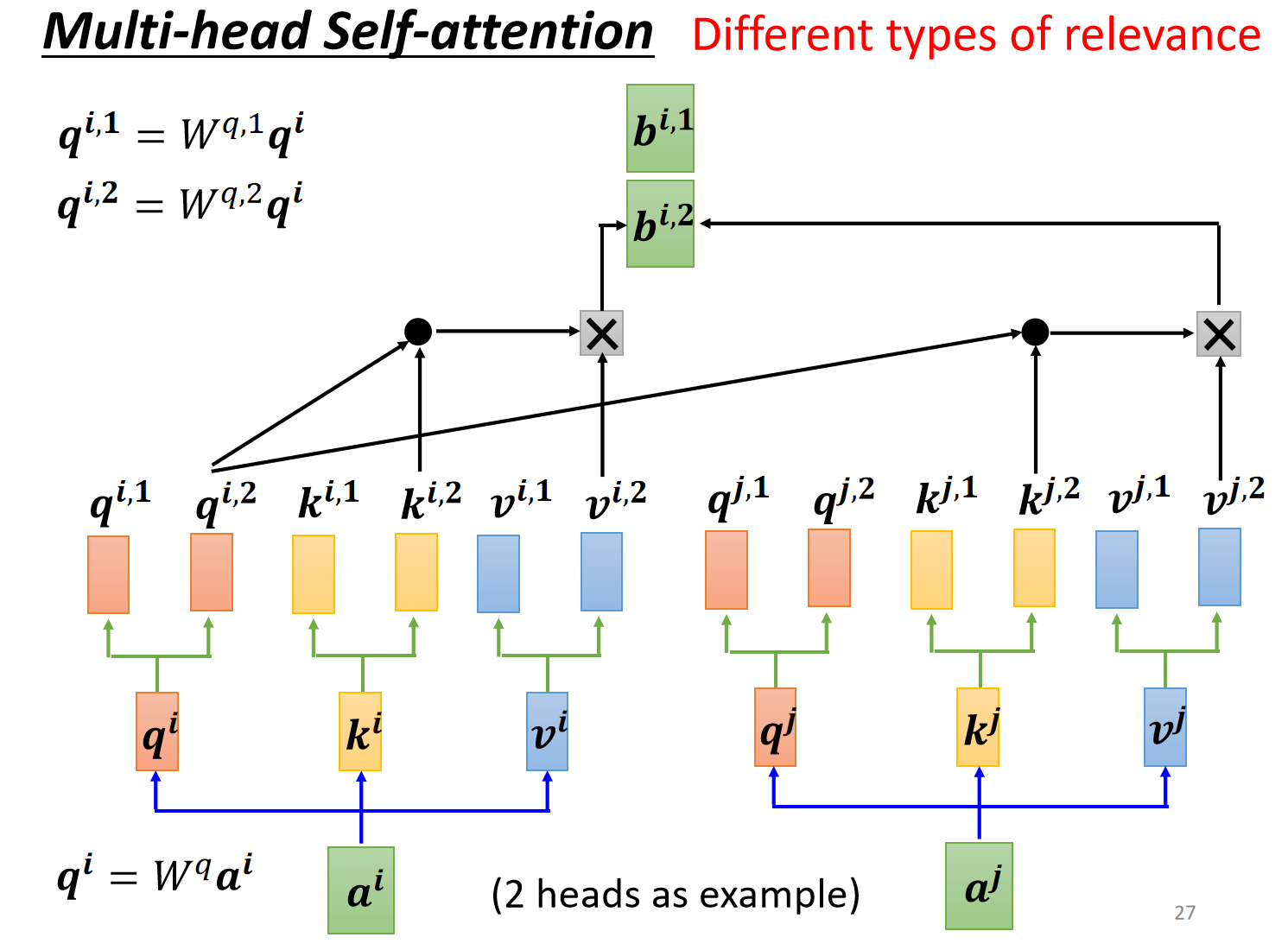
5.1 多头注意力(Multi-Head)
- 使用多组独立的 $(W^q, W^k, W^v)$
- 每组学习不同类型的关联特征
- 输出拼接后线性变换:
$$\text{Output} = \text{Concat}(head_1,…,head_h)W^o$$
5.2 位置编码(Positional Encoding)
自注意力本身不包含位置信息,需显式添加位置编码 $e^i$:
$$\tilde{a}^i = a^i + e^i$$
编码方式:
- 固定模式:正弦/余弦函数
$$e^i_t = \begin{cases}
\sin(\omega_k t) & i=2k \
\cos(\omega_k t) & i=2k+1
\end{cases}$$ - 可学习模式:随机初始化并训练更新
6. 与其他神经网络对比
| 特性 | Self-Attention | CNN | RNN |
|---|---|---|---|
| 感受野 | 动态全局 | 固定局部 | 顺序局部 |
| 长距离依赖 | 强 | 需多层堆叠 | 弱(梯度消失) |
| 并行计算 | 高 | 高 | 低 |
| 计算复杂度 | $O(n^2 d)$ | $O(k n d^2)$ | $O(n d^2)$ |
| 数据需求 | 大型数据集 | 中小数据集 | 中小数据集 |
- 与CNN关系:可视为动态感受野的复杂卷积
- 与RNN关系:解决了并行计算与长距离依赖问题
7. 核心应用
- Transformer:构成核心运算层(如Encoder/Decoder)
- NLP领域:
- BERT/GPT系列预训练模型
- 机器翻译、文本摘要、问答系统
- 计算机视觉:
- Vision Transformer (ViT)
- 目标检测(DETR)
- 语音处理:
- 语音识别(Conformer)
- 语音合成(Tacotron 2)
- 图神经网络:
- 节点分类(Graph Attention Networks)
总结
| 关键特征 | 核心价值 |
|---|---|
| 动态权重分配 | 根据上下文自适应调整重要性 |
| 全局感知能力 | 单层捕获长距离依赖 |
| 高度并行化 | 加速大规模数据处理 |
| 架构灵活性 | 适用于多种数据结构 |
| 多模态适应性 | 统一处理文本/语音/图像 |
Self-attention 通过模拟人脑的注意力机制,实现了从局部感知到全局理解的飞跃,成为现代深度学习架构的基石。