李宏毅机器学习-HW3 Notebook
这是我完成李宏毅机器学习2021作业3时记录的一些笔记 ,希望能对你有所帮助😊
😆 作业2没整出来什么,直接看SOTA 方法了,也就没什么笔记
作业要求
Homework 3 - Convolutional Neural Network
This is the example code of homework 3 of the machine learning course by Prof. Hung-yi Lee.
In this homework, you are required to build a convolutional neural network for image classification, possibly with some advanced training tips.
There are three levels here:
Easy: Build a simple convolutional neural network as the baseline. (2 pts)
Medium: Design a better architecture or adopt different data augmentations to improve the performance. (2 pts)
Hard: Utilize provided unlabeled data to obtain better results. (2 pts)
结果分析
直接跑原始代码,会发现train的acc显著高于val的acc,我们的模型在train_data上过拟合了,过分依赖训练数据甚至是某些局部特征,因此,需要采取一些措施来防止过拟合
我大致修改了这些地方:
- 使用数据增强
- 修改模型结构
- 超参数调整
Data Augmentation
对于一张食物图片,以我们人眼看来,将图片旋转少许角度,将图片横向翻转,改变图片的尺寸、亮度、对比度等,我们用肉眼依然能够分辨,但model就不一定了,因此,我们可以用数据增强来提升模型的泛化能力、鲁棒性,减轻一定程度的过拟合。
Data Augmentation并不直接修改原始数据,而是在样本加载时动态随机生成另一个新样本
问了下deepseek-v3
本指南将详细解析 torchvision.transforms 中各种数据增强方法的参数,并介绍如何使用 AutoAugment 和 RandAugment 这两种高级增强策略。
1. 基础几何变换方法
(1) RandomHorizontalFlip / RandomVerticalFlip
- 作用:随机水平或垂直翻转图像。
- 参数:
p(float): 翻转概率(默认0.5)。 - 示例:
1
transform = transforms.RandomHorizontalFlip(p=0.7) # 70%概率水平翻转
(2) RandomRotation
- 作用:随机旋转图像。
- 参数:
degrees(float or tuple): 旋转角度范围(如30表示±30°,(10, 30)表示10°~30°)。expand(bool): 是否扩大图像尺寸以容纳旋转后的内容(默认False)。fill(tuple): 旋转后空白区域的填充值(RGB格式,如(255, 0, 0)表示红色)。
- 示例:
1
transform = transforms.RandomRotation(degrees=(-15, 15), fill=(0, 0, 0)) # 旋转±15°,空白填黑色
(3) RandomResizedCrop
- 作用:随机裁剪并缩放到指定尺寸。
- 参数:
size(int or tuple): 目标尺寸(如224或(224, 224))。scale(tuple): 裁剪面积比例范围(如(0.08, 1.0)表示裁剪原图的8%~100%)。ratio(tuple): 宽高比范围(如(0.75, 1.33))。
- 示例:
1
transform = transforms.RandomResizedCrop(size=224, scale=(0.8, 1.0), ratio=(0.9, 1.1))
2. 颜色空间变换方法
(1) ColorJitter
- 作用:随机调整亮度、对比度、饱和度和色调。
- 参数:
brightness(float or tuple): 亮度调整范围(如0.2表示±20%)。contrast/saturation/hue: 类似亮度,但hue范围是[-0.5, 0.5]。
- 示例:
1
transform = transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1)
(2) RandomGrayscale
- 作用:以概率
p将图像转为灰度。 - 参数:
p(float): 灰度化概率(默认0.1)。
- 示例:
1
transform = transforms.RandomGrayscale(p=0.3) # 30%概率灰度化
3. 高级增强方法
(1) AutoAugment
- 作用:基于强化学习搜索的增强策略(针对特定数据集如 ImageNet、CIFAR10 优化)。
- 参数:
policy(str): 预定义策略(imagenet/cifar10/svhn)。interpolation(InterpolationMode): 插值方法(如BILINEAR)。
- 示例:
1
2
3
4
5from torchvision.transforms import AutoAugment, AutoAugmentPolicy
transform = transforms.Compose([
AutoAugment(policy=AutoAugmentPolicy.IMAGENET), # 使用ImageNet策略
transforms.ToTensor()
])
(2) RandAugment
- 作用:简化版 AutoAugment,随机选择
N种变换并统一强度M。 - 参数:
num_ops(int): 每次增强应用的变换数量(默认2)。magnitude(int): 强度值(0~30,默认9)。num_magnitude_bins(int): 强度离散化级别(默认31)。
- 示例:
1
2
3
4
5from torchvision.transforms import RandAugment
transform = transforms.Compose([
RandAugment(num_ops=3, magnitude=9), # 随机选3种变换,强度9
transforms.ToTensor()
])
(3) TrivialAugmentWide
- 作用:更简单的 RandAugment 变体,无需调参。
- 示例:
1
2
3
4
5from torchvision.transforms import TrivialAugmentWide
transform = transforms.Compose([
TrivialAugmentWide(), # 自动选择变换和强度
transforms.ToTensor()
])
4. 其他实用方法
(1) GaussianBlur
- 作用:高斯模糊(模拟焦距变化)。
- 参数:
kernel_size(int or tuple): 卷积核大小(必须为奇数)。sigma(float or tuple): 标准差范围(如(0.1, 2.0))。
- 示例:
1
transform = transforms.GaussianBlur(kernel_size=5, sigma=(0.1, 2.0))
(2) RandomErasing
- 作用:随机擦除图像区域(类似 Cutout)。
- 参数:
p(float): 擦除概率。scale/ratio: 擦除区域的面积和宽高比范围。
- 示例:
1
transform = transforms.RandomErasing(p=0.5, scale=(0.02, 0.2), ratio=(0.3, 3.3))
5. 完整示例代码
1 | |
6. 选择建议
- 简单任务:基础几何变换 +
ColorJitter。 - 复杂任务:优先尝试
AutoAugment(预训练策略)或RandAugment(需调参)。 - 资源有限:使用
TrivialAugmentWide(免调参)。
通过合理组合这些方法,可以显著提升图像分类模型的泛化能力! 🚀
反正我试了一下几种方法,也包括自己diy的,竟然TrivialAugmentWide的效果是最好的,看来它必然有它的道理
CNN架构
1 | |
Conv2d
先解释下nn.Conv2d(3, 64, 3, 1, 1),分别对应 in_channels, out_channels, kernel_size, stride, padding
- 输入通道(
in_channels):输入数据的特征层数(如RGB图像的3通道、前一层的输出通道数)。 - 输出通道(
out_channels):卷积后生成的特征图数量(即卷积核的数量)。 - 每个输出通道由一个独立的卷积核生成,该卷积核会扫描所有输入通道并加权求和。
输入输出通道的设计逻辑
(1) 通道数的变化规律
- 经典CNN模式:
- 随着网络加深,空间尺寸(
H, W)逐渐减小(通过池化或大步长卷积)。 - 通道数逐渐增加(如
3 → 64 → 128 → 256),以保留更多高阶特征信息。 - 原因:空间信息压缩后,需增加通道维度来维持信息容量。
- 随着网络加深,空间尺寸(
(2) 为什么需要多输出通道?
- 多样性特征提取:不同卷积核检测不同模式(如边缘、颜色、纹理)。
- 示例:第一层的输出通道可能分别对应“水平边缘”、“垂直边缘”、“红色区域”等特征。
- 特征组合:深层卷积通过混合多通道输入,生成更复杂的特征(如“眼睛+鼻子”组合为人脸)。
(3) 输入输出通道的约束
- 输入通道必须匹配:
- 前一层的
out_channels必须等于后一层的in_channels。 - 例如:
Conv2d(64, 128)的下一层必须是Conv2d(128, ...)。
- 前一层的
- 输出通道自由选择:
- 通常取2的幂次(如64、128、256),方便GPU内存对齐优化。
卷积过程
可视化图: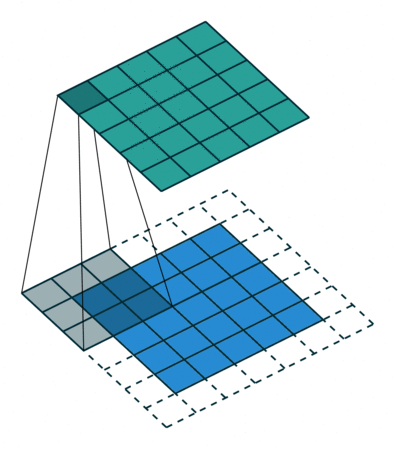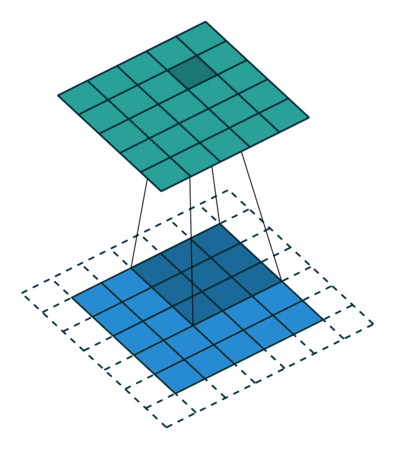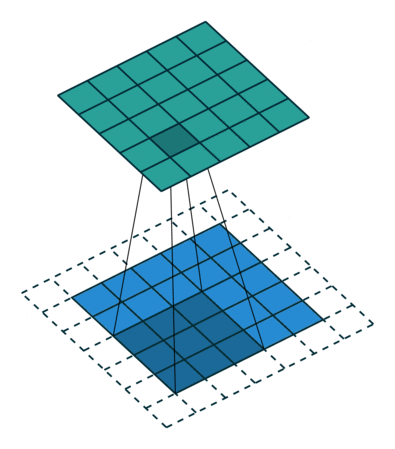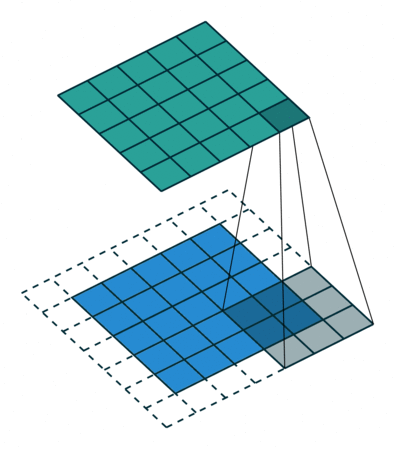
半监督学习
- 原始数据集中有很大一部分是没有
label的,如果想要提高模型准确性与泛化能力,必须利用好这部分数据,这就涉及到半监督学习semi-supervised learning - 具体就是先用已有模型去预测数据,置信度大于
threshold就认为这个label是正确的,将其加入训练集,进入下一轮训练 - 具体需要我们做的就是
filter一下即可
1 | |
mask
- 这里比较有趣的是
mask,为什么能直接索引数据了,这不是一个判断条件么?其实这是一种高效张量操作方式1
2
3mask = max_probs >= threshold
selected_imgs = img[mask]
selected_labels = preds[mask]
本质:布尔掩码索引(Boolean Masking)
PyTorch 的张量(Tensor)支持类似 NumPy 的 高级索引(Advanced Indexing),其中布尔掩码索引是核心特性之一:
关键点
max_probs >= threshold会生成一个与原张量形状相同的布尔张量(Tensorofbool)img[mask]会返回所有mask为True位置对应的数据子集1
2
3
4
5mask = max_probs >= threshold # 生成布尔张量(True/False)
selected_imgs = img[mask] # 用布尔张量筛选数据
max_probs = tensor([0.9, 0.6, 0.8, 0.3])
mask = max_probs >= 0.7 # tensor([ True, False, True, False])