李宏毅机器学习-Transformer
这是我时记录的一些笔记 ,希望能对你有所帮助😊
1. 序列到序列 (Seq2seq) 任务
在深度学习领域,许多任务都可以被归纳为“序列到序列”(Sequence-to-sequence, Seq2seq)问题。这类任务的特点是输入一个序列,模型需要生成另一个序列,并且输出序列的长度可能与输入序列不同,由模型自行决定。
常见的Seq2seq应用包括:
- 机器翻译: 将一种语言的句子(序列)翻译成另一种语言的句子(序列)。
- 语音识别: 将一段语音信号(序列)转换成文字(序列)。
- 文本转语音 (TTS): 将文字(序列)合成对应的语音波形(序列)。
- 问答与对话系统: 将问题或对话上下文(序列)生成回答(序列)。
甚至一些看似不相关的任务,如句法分析、多标签分类和目标检测,也可以巧妙地转化为Seq2seq问题进行处理。
2. Transformer:Seq2seq模型的革命
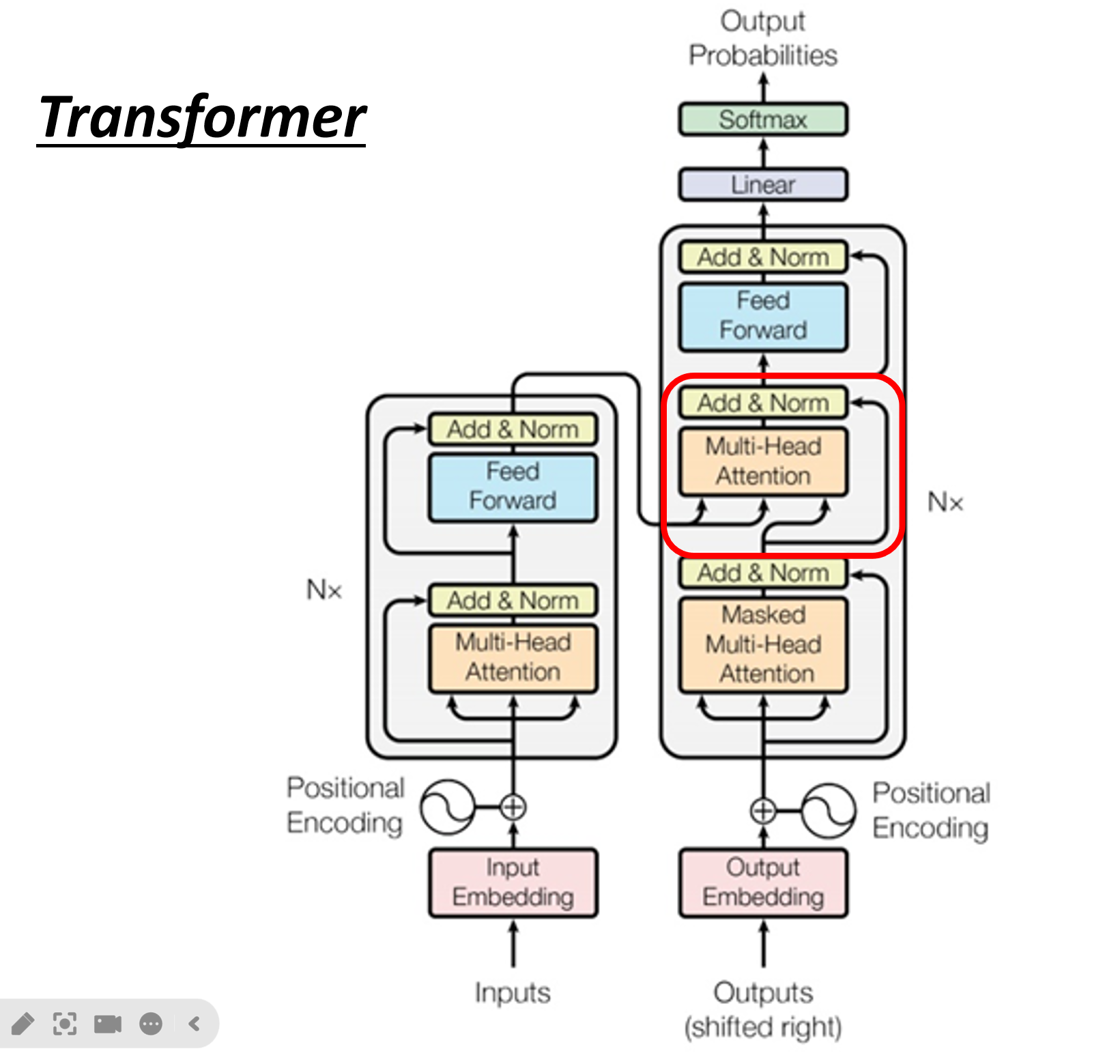
Transformer是一个完全基于注意力机制的Seq2seq模型,它摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构。其核心思想在论文 “Attention Is All You Need” 中被提出,并迅速成为自然语言处理(NLP)领域的标准架构。
Transformer模型主要由两部分组成:编码器 (Encoder) 和 **解码器 (Decoder)**。
- 编码器 (Encoder): 负责处理输入序列,并将其转换成一组富含上下文信息的向量表示。
- 解码器 (Decoder): 利用编码器的输出,并结合已经生成的部分输出,逐个生成目标序列的元素。
论文参考:
Attention Is All You Need: https://arxiv.org/abs/1706.03762
Sequence to Sequence Learning with Neural Networks: https://arxiv.org/abs/1409.3215
3. 编码器 (Encoder) 详解
编码器的作用是“理解”输入序列。它由N个相同的层堆叠而成,每一层都包含两个核心子模块。
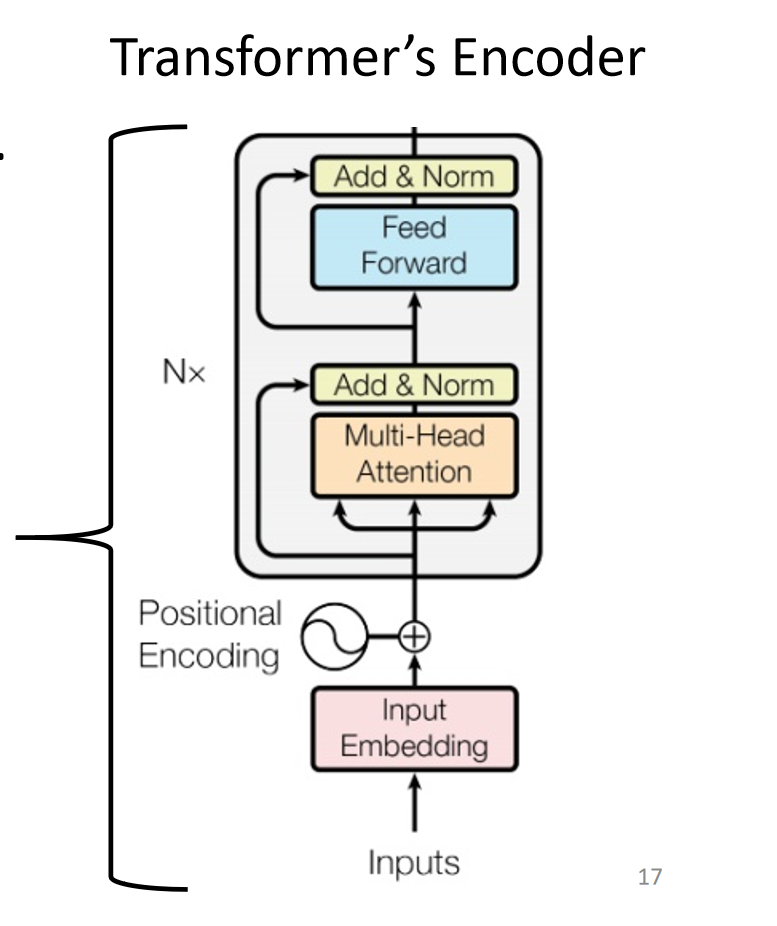
多头自注意力 (
Multi-Head Self-Attention)这个模块让输入序列中的每个词都能“关注”到序列中的所有其他词,从而计算出每个词在特定上下文中的表示。它解决了长距离依赖的问题,并且可以并行计算。
前馈神经网络 (
Feed Forward Network)这是一个简单的全连接前馈网络,对自注意力模块的输出进行进一步的非线性变换。
关键细节:
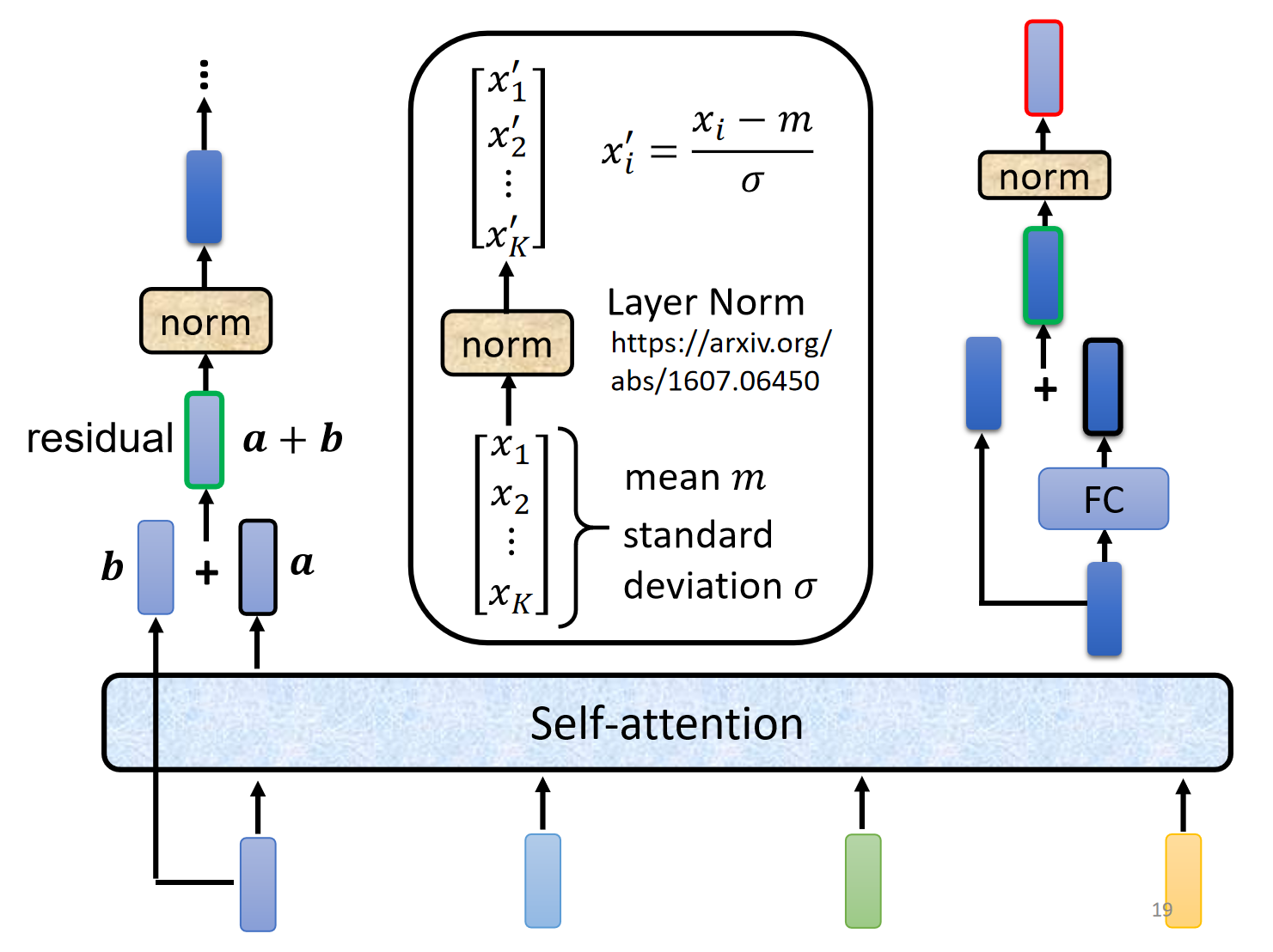
残差连接 (Residual Connection) 与层归一化 (Layer Normalization): 每个子模块(自注意力和前馈网络)的输出都与该模块的输入进行相加(残差连接),然后进行层归一化(
Layer Norm)。这有助于防止梯度消失,加速模型训练,并稳定训练过程。位置编码 (Positional Encoding): 由于自注意力机制本身不包含序列的位置信息,我们需要在输入时额外加入一个“位置编码”向量,来告诉模型每个词在句子中的绝对或相对位置。
相关论文:
On Layer Normalization in the Transformer Architecture: https://arxiv.org/abs/2002.04745
PowerNorm: Rethinking Batch Normalization in Transformers: https://arxiv.org/abs/2003.07845
4. 解码器 (Decoder) 详解
解码器的任务是生成输出序列。它同样由N个相同的层堆叠而成,但每层比编码器多了一个模块。
带掩码的多头自注意力 (Masked Multi-Head Self-Attention)
与编码器类似,但增加了一个“掩码”(
Mask)。这个掩码确保在预测第 i 个词时,模型只能关注到它前面已经生成的 1 到 i-1 个词,而不能“看到”未来的词。这是为了保证解码过程的自回归(Autoregressive)特性。交叉注意力 (Cross-Attention)
这是连接编码器和解码器的桥梁。在这个模块中,Query 来自于解码器的上一个模块(带掩码的自注意力),而 Key 和 Value 则来自于编码器的最终输出。这使得解码器在生成每个词时,能够关注到输入序列的所有部分,并从中提取最相关的信息。
前馈神经网络 (Feed Forward Network)
与编码器中的前馈网络功能相同。
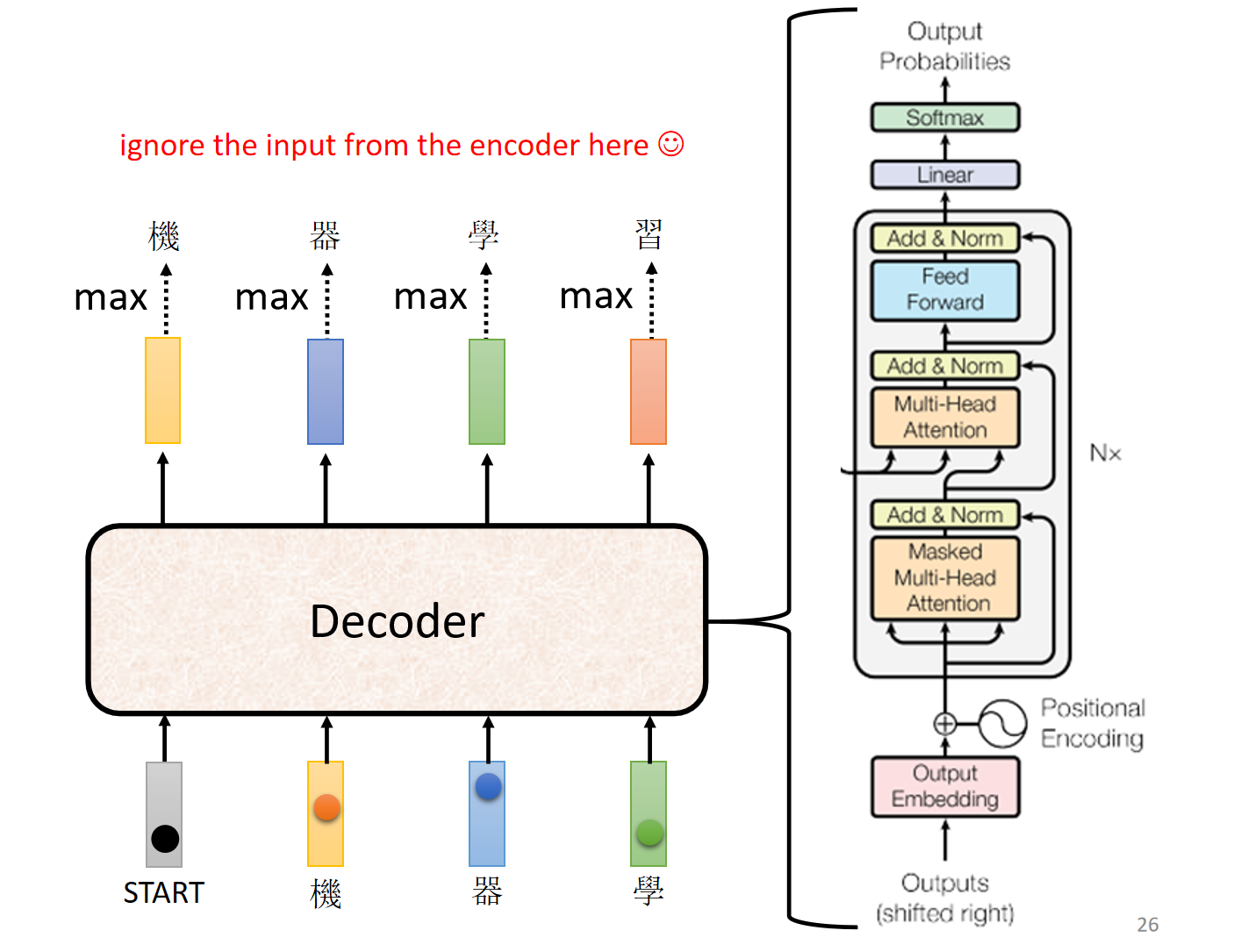
解码过程:自回归 (Autoregressive, AT)
见上图,解码器生成输出是一个逐词进行的过程:
- 输入一个特殊的起始符
<BEGIN>。 - 解码器根据
<BEGIN>和编码器的输出,生成第一个词(例如“机”)。 - 将已生成的“机”作为下一步的输入,解码器再生成第二个词(例如“器”)。
- 重复此过程,直到解码器生成一个特殊的终止符
<END>为止。
对比:非自回归 (Non-autoregressive, NAT)
NAT解码器尝试一次性生成所有输出,而不是逐词生成。这样做可以实现完全并行,速度更快,但在某些任务上,由于问题的多模态性(一个输入可能对应多个合理输出),其性能通常不如AT模型。
5. 训练技巧与策略
Teacher Forcing: 在训练阶段,为了提高效率和稳定性,无论模型上一步预测出什么词,我们总是将正确的上一个词作为当前步的输入。这就像有一个“老师”在不断纠正模型的路径。
Exposure Bias: Teacher Forcing 导致了训练与测试之间的不匹配(
mismatch)。在测试时,模型必须依赖自己之前生成的(可能错误的)词,这种差异被称为“暴露偏差”。Scheduled Sampling: 一种缓解
Exposure Bias的策略。在训练过程中,以一定概率选择使用模型的上一时刻预测输出或真实的标签作为当前时刻的输入。Beam Search: 在解码(生成)阶段,为了找到比贪心策略(每次都选概率最高的词)更优的输出序列,可以使用束搜索。它在每一步都保留k个最可能的候选序列,并在下一步从这k个序列出发继续扩展,从而在全局上找到更好的解。
相关论文:
The Curious Case of Neural Text Degeneration: https://arxiv.org/abs/1904.09751
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks: https://arxiv.org/abs/1506.03099
6. 总结
Transformer凭借其强大的并行计算能力和对长距离依赖的出色建模,彻底改变了Seq2seq任务的格局。其核心的自注意力机制、多头注意力、位置编码以及Encoder-Decoder架构共同构成了这一强大模型的基础,并催生了BERT、GPT等一系列在AI领域产生深远影响的模型。