李宏毅机器学习-GAN
这是我学习李宏毅机器学习时记录的一些笔记 ,希望能对你有所帮助😊
1. 生成模型简介 (Introduction of Generative Models)
生成模型的核心思想是创建一个能够学习数据内在规律和分布的神经网络,这个网络被称为**生成器 (Generator)**。生成器的任务是从一个简单的、已知的概率分布(如正态分布或均匀分布)中采样一个随机向量(通常称为噪声 z),并将其转换为一个复杂的、高维的数据样本(如一张图片)。
这个过程好比让一个神经网络学习如何“创造”。我们给它一个简单的随机种子,它就能“画”出一张逼真的图像。
为什么需要生成一个分布?
在许多任务中,同一个输入可能对应多个合理的输出。例如:
视频预测: 预测视频的下一帧时,角色可能向左走也可能向右走,两种都是合理的结果。如果模型只输出一个确定的、所有可能性的平均结果,画面就会变得模糊不清。
需要创造力的任务: 像绘画或对话机器人这样的任务,我们希望模型能有“创造力”,对同一个输入(如“画一个红眼睛的角色”)能产生多样化的输出,而不是每次都生成一模一样的结果。
通过让生成器学习输出一个分布,模型就可以捕捉到这种不确定性,从而生成多样化且清晰的结果。
2. 生成对抗网络 (GAN)
基本解释
生成对抗网络(GAN)是一种强大的生成模型框架,它通过一种“对抗”或“博弈”的方式进行训练。GAN由两个核心部分组成:
生成器 (Generator, G):
角色: 一个“伪造者”或“艺术家”。
任务: 学习真实数据的分布,并尝试生成尽可能逼真、能够以假乱真的数据(例如,生成动漫头像)。
判别器 (Discriminator, D):
角色: 一个“鉴赏家”或“警察”。
任务: 学习如何区分真实数据和由生成器生成的“假”数据。对于真实数据,它应该输出高分(接近1);对于假数据,它应该输出低分(接近0)。
对抗训练过程
GAN的训练过程是一个动态的、交替优化的过程,就像生成器和判别器在进行一场永无休止的“军备竞赛”:
第1步:固定G,训练D
从真实数据库中采样一批真实图片,并让生成器G生成一批假图片。
将这两批图片都喂给判别器D。
D的目标是给真实图片打高分,给假图片打低分。我们根据这个目标更新D的参数,让它的鉴别能力越来越强。
第2步:固定D,训练G
生成器G生成一批假图片,并将其输入到固定不变的判别器D中。
G的目标是“欺骗”D,即希望D给这些假图片打出尽可能高的分数。
我们根据这个目标,反向传播梯度来更新G的参数。这样,G就会学习如何生成更逼真的图片来迷惑D。
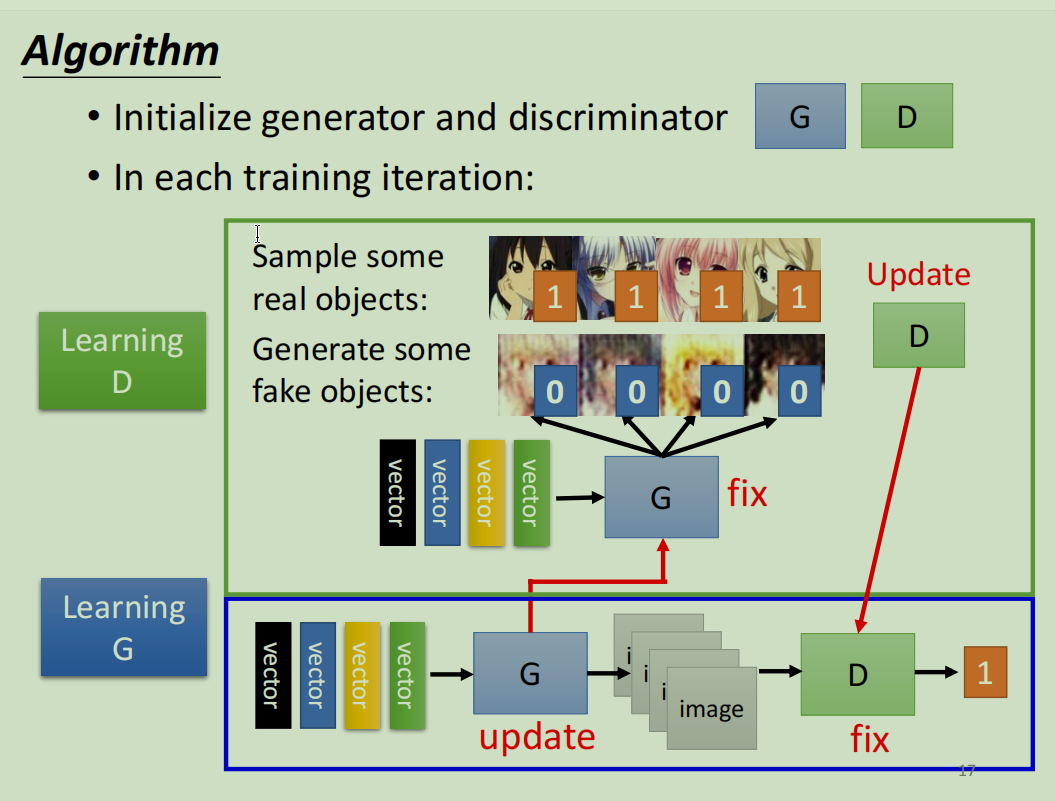
这个过程不断迭代,最终理想状态下,生成器G能够生成与真实数据无法区分的样本,而判别器D再也无法分辨真假(对任何输入的打分都接近0.5)。这个过程就像是亦敌亦友的共同进化。
[图片:展示GAN训练过程中,生成的动漫头像从模糊的噪声逐渐变得清晰、逼真的演进过程]
开创性论文:
- Generative Adversarial Nets: https://arxiv.org/abs/1406.2661
3. GAN背后的理论
GAN的最终目标是让生成器G学习到的数据分布 $P_G$ 尽可能地接近真实数据的分布 $P_{data}$。我们可以用一个衡量两个分布之间差异的指标——散度 (Divergence) 来描述这个目标。
$$
G∗=argmin Div(PG,Pdata)
$$
虽然我们无法直接计算这两个复杂分布之间的散度,但GAN巧妙地利用判别器D来间接实现这一目标。
在原始GAN的理论中,判别器D的优化目标(最大化V(G,D))实际上是在计算 PG 和 Pdata 之间的**JS散度 (Jensen-Shannon divergence)**。
$$
V(G,D)=E_{y∼P_{data}}[logD(y)]+E_{y∼P_G}[log(1−D(y))]
$$
当判别器D被训练到最优时,生成器G的优化目标就等价于最小化 PG 和 Pdata 之间的JS散度。==因此,整个GAN的 min-max 博弈过程,实际上就是在推动生成分布去逼近真实分布==
[图片:展示 PG 和 Pdata 两个分布,并用箭头表示GAN的目标是让 PG 尽可能靠近 Pdata]
f-GAN 论文 (探索不同散度):
- f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization: https://arxiv.org/abs/1606.00709
4. 训练GAN的技巧
GAN的训练是出了名的困难和不稳定,常被称为“炼丹”。以下是一些关键的挑战和改进技巧:
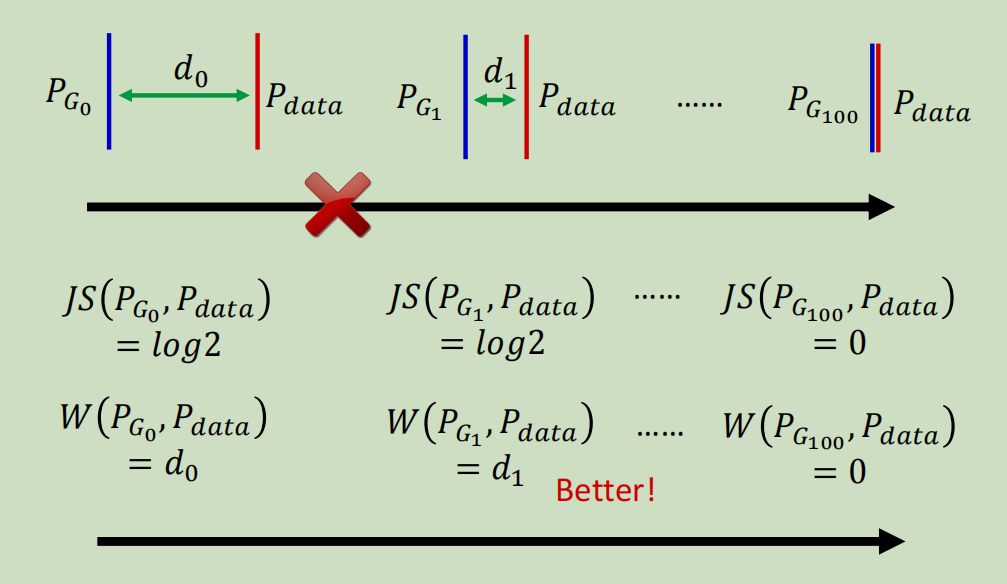
挑战1:JS散度的问题与WGAN
问题: 在高维空间中,两个分布 PG 和 Pdata 几乎不可能有重叠。当它们没有重叠时,JS散度是一个常数(log2),这导致生成器的梯度为0,无法学习。
解决方案: Wasserstein GAN (WGAN) 提出使用
Wasserstein距离(又称“推土机距离”)来替代JS散度。- 优势: 即使两个分布没有重叠,Wasserstein距离仍然能提供一个有意义的、平滑的度量,反映了它们之间的“远近”。这为生成器提供了持续有效的梯度。
实现: WGAN通过对判别器(在WGAN中称为Critic)施加1-Lipschitz约束来实现。为了满足这个约束,后续工作提出了更稳定的方法:
WGAN-GP (Gradient Penalty): 通过对Critic的梯度添加惩罚项来约束它。
谱归一化 (Spectral Normalization): 一种更简单有效的约束方法。
WGAN 相关论文:
Wasserstein GAN: https://arxiv.org/abs/1701.07875
Improved Training of Wasserstein GANs: https://arxiv.org/abs/1704.00028
Spectral Normalization for Generative Adversarial Networks: https://arxiv.org/abs/1802.05957
挑战2:生成器与判别器的平衡
生成器和判别器的学习能力需要“棋逢对手”。如果判别器太强,生成器梯度会消失;如果判别器太弱,生成器则学不到有效信息。保持二者同步发展是训练成功的关键。
挑战3:GAN用于序列生成
将GAN用于生成文本等离散序列是困难的,因为从概率分布中“采样”的这个操作是不可导的,导致梯度无法从判别器回传到生成器。通常需要借助强化学习 (Reinforcement Learning) 的思想来解决,但这会使训练变得更加复杂。
更多训练技巧参考:
GAN Hacks (GitHub): https://github.com/soumith/ganhacks
DCGAN paper: https://arxiv.org/abs/1511.06434
Improved Techniques for Training GANs: https://arxiv.org/abs/1606.03498
BigGAN paper: https://arxiv.org/abs/1809.11096
5. 条件生成 (Conditional Generation)
无条件GAN生成的内容是完全随机的,我们无法控制。条件GAN (Conditional GAN, cGAN) 通过引入一个额外的条件输入 x(如文本描述、图像等),来指导生成器生成特定的内容。
工作原理:
- 生成器: 将随机噪声
z和条件x同时作为输入,生成对应的图像 y=G(x,z)。 - 判别器: 不仅要判断输入的图像
y是否真实,还要判断y是否与条件x匹配。
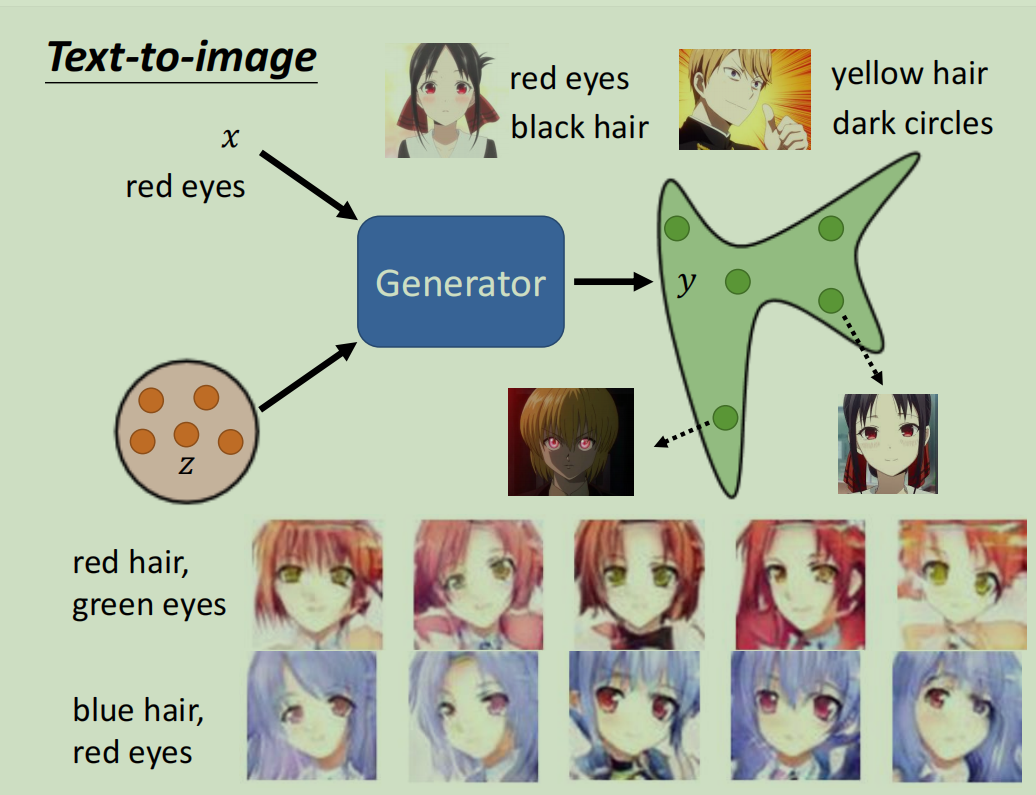
应用实例 (pix2pix):
条件GAN在图像到图像翻译 (Image-to-Image Translation) 任务中非常成功,例如:
- 从标签图生成街景
- 从线稿生成手提包
- 从黑白照片生成彩色照片
- 从航拍图生成地图
相关论文:
Conditional Generative Adversarial Nets: https://arxiv.org/abs/1411.1784
Image-to-Image Translation with Conditional Adversarial Networks (pix2pix): https://arxiv.org/abs/1611.07004
6. 从非成对数据中学习
pix2pix等条件GAN需要大量的成对 (paired) 训练数据(如线稿和对应的实物图),而这在现实中往往难以获取。CycleGAN 解决了这个问题,它能从非成对 (unpaired) 的数据中学习两个领域之间的转换。
例如,我们只需要一个“真人照片”文件夹和一个“动漫头像”文件夹,不需要任何一张照片和它对应的动漫头像。
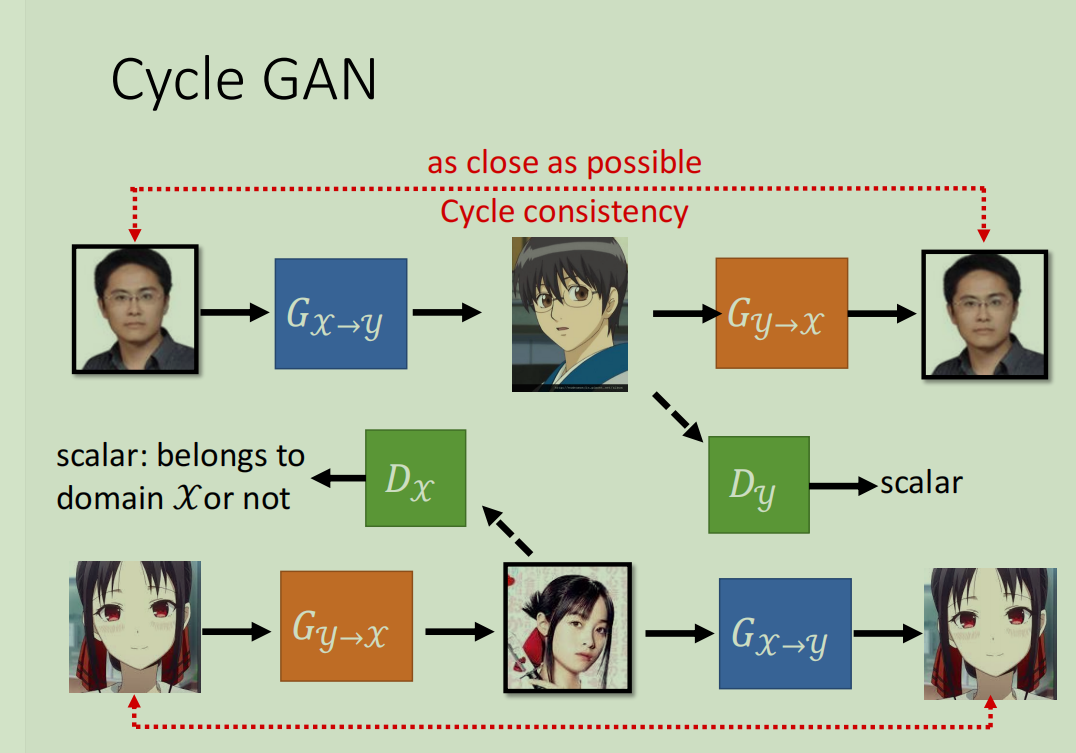
核心思想:循环一致性损失 (Cycle Consistency Loss)
CycleGAN同时训练两个生成器:GX→Y (从领域X到Y) 和 GY→X (从领域Y到X)。其核心约束是循环一致性:
将一张真人照片 x 通过 GX→Y 转换成动漫头像。
再将这个生成的动漫头像通过 GY→X 转换回真人照片。
这个“循环”回来的照片应该和原始的输入照片 x 尽可能一致。
这个约束确保了生成器在转换风格的同时,会保留原始图像的内容,而不是随意生成一个目标域中不相关的图像。
相关论文:
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (CycleGAN): https://arxiv.org/abs/1703.10593
(类似工作) DiscoGAN: https://arxiv.org/abs/1703.05192
(类似工作) DualGAN: https://arxiv.org/abs/1704.02510
(多领域) StarGAN: https://arxiv.org/abs/1711.09020
7. 生成模型的评估
评估生成模型的好坏是一个开放性难题,因为“好”本身是一个主观概念。我们通常从两个维度进行评估:
1. 图像质量 (Quality)
- 方法: 将生成的图像输入到一个预训练好的图像分类器(如Inception Net)中。如果生成的图像清晰且包含明确的物体,分类器会给出一个非常集中的概率分布(例如,99%的概率是“狗”)。如果图像模糊不清,则分布会比较分散。
2. 图像多样性 (Diversity)
问题: 生成器可能会陷入模式坍塌 (Mode Collapse),即无论输入什么随机噪声,都只生成少数几种或一种图像,缺乏多样性。
模式丢失 (Mode Dropping): 生成器可能只学会了真实数据分布中的一部分模式,而完全忽略了其他模式。
常用评估指标:
Inception Score (IS): 结合了图像质量和多样性。分数越高越好。但它有缺陷,比如无法检测到是否过拟合了训练数据。
Fréchet Inception Distance (FID): 目前更常用、更可靠的指标。它通过比较真实图像和生成图像在特征空间中的分布相似度来打分。FID分数越低越好。
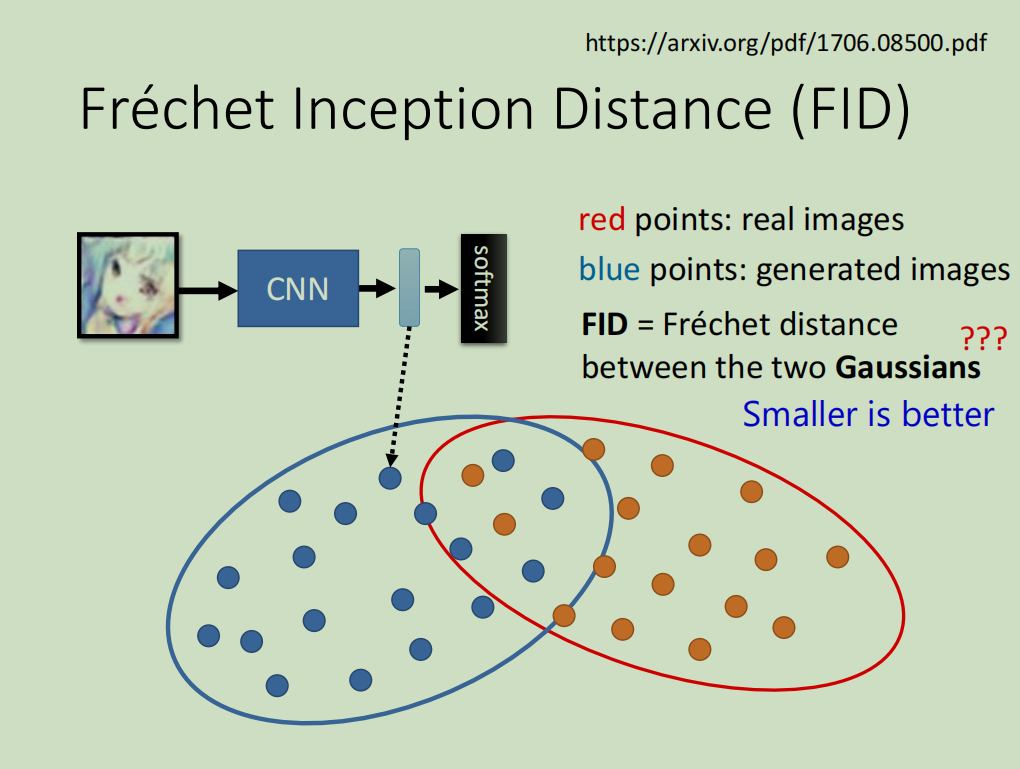
相关论文:
A Note on the Inception Score: https://arxiv.org/abs/1801.01973
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium: https://arxiv.org/abs/1706.08500
Are GANs Created Equal? A Large-Scale Study: https://arxiv.org/abs/1711.10337
Pros and Cons of GAN Evaluation Measures: https://arxiv.org/abs/1802.03446