李宏毅机器学习-大模型训练
这是我学习2025版本大模型训练部分时记录的一些笔记 ,希望能对你有所帮助😊
大型语言模型「预训练-对齐」
这份笔记旨在探讨当前大型语言模型(LLM)主流的「预训练-对齐」(Pretrain-Alignment) 开发范式。我们将深入了解预训练阶段的强大之处,以及对齐阶段的关键作用与其内在的限制。
什么是「预训练-对齐」范式?
目前主流的 LLM 开发流程主要包含三个阶段,共同构成了「预训练-对齐」范式。
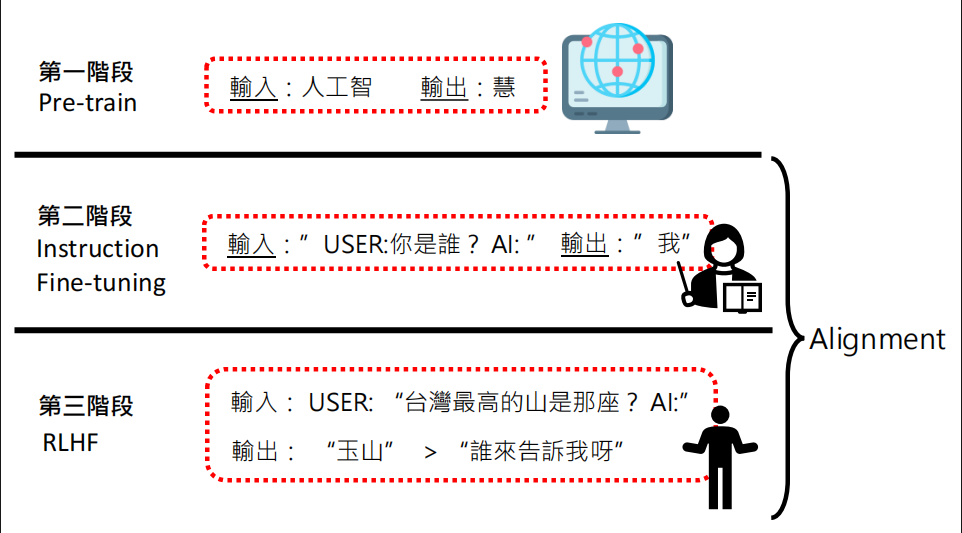
第一阶段:预训练 (Pre-training)
- 目标:让模型学习语言的规律、事实知识和推理能力。
- 方式:在海量、多元的文本资料上进行训练,通常是预测下一个词(token)。例如,输入「人工智」,模型要能输出「慧」。
- 特性:这个阶段的模型虽然学到了丰富的知识,但通常不遵循人类的指令,直接使用时可能答非所问或难以控制。
第二阶段:指令微调 (Instruction Fine-tuning)
- 目标:教导模型理解并遵循人类的指令,使其行为与使用者对齐 (Alignment)。
- 方式:使用高品质的「指令-回答」资料对进行微调。例如,输入「USER:你是谁? AI:」,模型需要学会回答「我」。
第三阶段:人类反馈的增强学习 (RLHF)
- 目标:进一步根据人类的偏好优化模型的输出,使其更符合「有帮助、无害、诚实」等原则。
- 方式:让人类对模型生成的多个回答进行排序,训练一个奖励模型(Reward Model),再通过强化学习(RL)算法来最大化奖励分数。例如,对于问题「台湾最高的山是哪座?」,模型生成的「玉山」会比「谁来告诉我呀」获得更高的偏好。
Alignment 的力量与特性
Alignment 虽然看似只是微调,但它对模型的最终表现有着决定性的影响,如同「画龙点睛」。
1. 对齐前后的巨大行为差异
- 预训练模型:以 LLaMA-2-7b-base 为例,当被问及「What is Machine Learning?」,它会像网络文章一样续写,内容正确但格式不像是对话。
- 对齐后模型:以 LLaMA-2-7b-chat 为例,同样的问题,它会给出结构化、清晰且像是助手在回答问题的答案。
2. Alignment 的关键:资料品质远胜于数量
- LLaMA 2 的经验:研究发现,使用数万笔高品质、由人工标注的 SFT (Supervised Fine-tuning) 资料,效果远胜于使用数百万笔品质参差不齐的第三方资料。LLaMA 2 最终仅用了 27,540 笔 SFT 资料就达到了高品质的结果。
- LIMA 的启示:(“Less Is More”) 另一项研究 LIMA 仅用 1,000 个精心挑选的范例进行微调,就达到了惊人的效果。这证明了只要对齐资料的品质足够高、风格足够多样,模型就能学会泛化到各种未见的指令类型。
3. 对齐资料的来源与影响
对齐资料的来源(Domain)对模型在特定领域的表现有显著影响。「点睛」的位置非常重要。
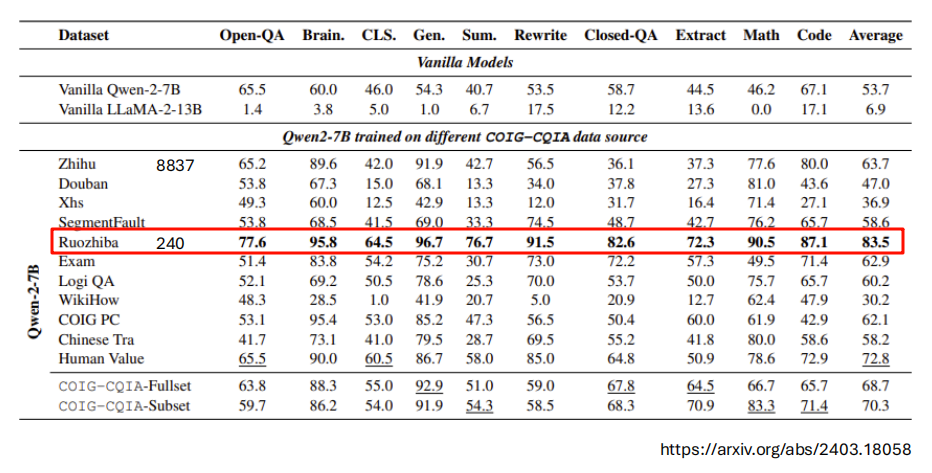
- 从表格中可以看出,使用特定领域的高品质资料(如 Ruozhiba,弱智吧)能大幅提升模型在相应能力(如数学、逻辑)上的表现,即使资料量非常少(仅 240 笔)。
- 相关论文: https://arxiv.org/abs/2403.18058
Alignment 的高效实践方法
鉴于高品质人工标注资料的昂贵,社群发展出多种高效的对齐方法。
1. 知识蒸馏 (Knowledge Distillation)
- 概念:使用一个强大的、已经对齐好的「老师模型」(如 ChatGPT、Gemini)来产生大量的「指令-回答」资料,再用这些资料去微调自己的「学生模型」。
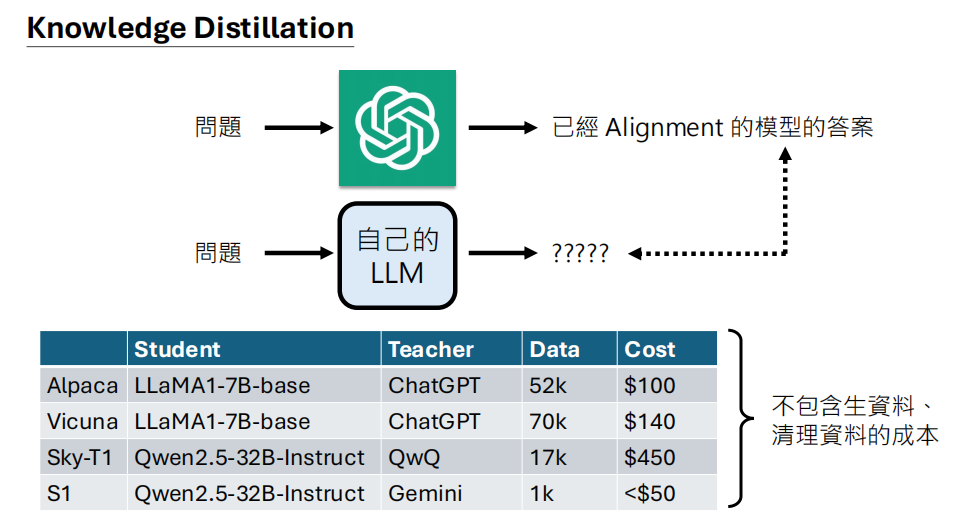
- AlpaGasus:此方法进一步提出,可以用老师模型(如 ChatGPT)作为「品质评估员」,过滤掉品质不佳的蒸馏资料,从而实现用更少的资料、更快的训练,达到更强的性能。
2. 非指令式微调 (Non-instructional Fine-tuning)
- 概念:这是一种创新的蒸馏方法,不直接复制问答对。而是从任意文本中取前半句,让老师模型续写后半句,然后训练学生模型去模仿老师模型的续写风格和知识。这种方法隐性地传递了老师模型的「世界模型」。
3. Alignment 真的很简单吗?新观点的涌现
研究表明,LLM 在预训练阶段可能已经具备了遵循指令的能力,只是需要被「解锁」。
模型行为差异的真相:研究《The Unlocking Spell on Base LLMs》发现,对齐前后的模型在绝大多数情况下,预测下一个词的概率分布是相似的 (Unshifted)。只有在少数关键词(如对话开头的 “Sure”, “Hello” 等)上,概率分布被显著改变 (Shifted)。这意味着 Alignment 更像是在引导模型使用它已有的知识,而不是教它新知识。
Response Tuning:与传统的「指令微调」(Instruction Tuning) 不同,RT 只计算「回答」部分的损失,而不计算「指令」部分的损失。实验表明,RT 的效果与 IT 相当,甚至更好。这再次佐证了模型在预训练后已能理解指令,微调的重点是教会它如何回答。

无需微调的指令遵循:更有甚者,研究发现仅通过设计简单的「规则适配器」(Rule-Based Adapter) 来修改词汇的输出概率,就可以让一个预训练模型在没有任何微调的情况下遵循指令。
Self-Alignment:上述发现解释了为何模型可以「自我对齐」。例如,一个未经对齐的模型可以先生成多个候选答案,然后再根据给定的评分指示,自己评估哪个答案最好,从而实现对齐。
Pretrain 的威力与极限
既然 Alignment 只是「点睛」,那么 LLM 的真正威力来源于 Pretrain 阶段。
- Pretrain 的力量源泉:资料的多样性
- 关键在于改写:
Paraphrasing实验证明,如果预训练资料中只包含单一形式的陈述(例如「A是B」),即使在对齐阶段学习了问答格式,模型也无法回答关于这些知识的问题。然而,如果在预训练资料中加入同一知识的多种不同表述方式(改写),模型就能学会知识的抽象表示,并能泛化到问答任务上,准确率从 0% 跃升至 96%。
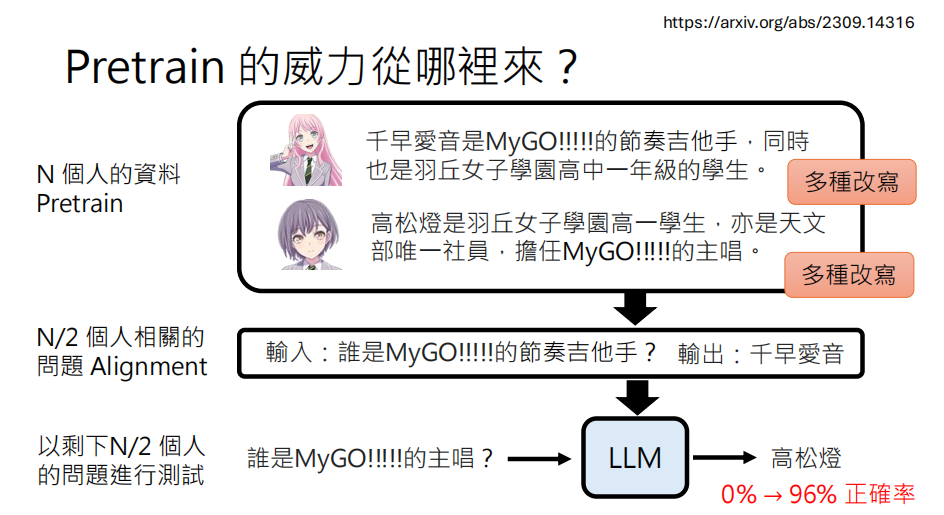
- 结论:预训练阶段看过大量、各式各样的资料是模型能力的核心。
- 相关论文: https://arxiv.org/abs/2309.14316
2. 预训练资料的规模与品质
- 规模:当前顶尖模型的预训练资料量极为庞大。例如,LLaMA 3 使用了约 15T tokens,DeepSeek-V3 使用了 14.8T tokens。
- 相关论文 (LLAMA 3): https://arxiv.org/abs/2407.21783
- 品质:资料品质至关重要。高品质的资料可以让模型用更少的 tokens 达到更高的性能。例如,研究显示使用经过精心过滤和合成的数据集(如 phi-1),一个较小的模型(350M)可以超越在更多、但品质较杂乱的资料上训练的更大模型。
- 资料与模型的权衡:在有限的算力下,并非资料越多越好。因为使用过多资料意味着模型需要缩小。研究表明,模型大小和资料量之间存在一个最佳的平衡点,以达到最低的训练损失。
Alignment 的极限与挑战
尽管 Alignment 很强大,但它并非万能,存在其固有的极限。

1. 难以学习新知识,只会强化已知
- 模仿的虚假承诺:研究发现,通过知识蒸馏微调的模型(Imitation Model)虽然能模仿老师模型的风格,但在回答事实性问题时,很容易产生「幻觉」或事实性错误。这表明模型只是在强化和重新组织它在预训练阶段已经学到的知识,而不是真正学会老师模型的新知识。
- 知识的边界:研究将知识分为「已知」(Known) 到「未知」(Unknown) 四个层次。结果显示,微调对「Maybe Known」(模型可能知道但不确定)的知识最有帮助。对于模型完全不知道的「Unknown」知识,微调几乎没有效果,并且很容易导致在已知知识上的过拟合。
2. 预训练的后遗症:难以根除的偏见
- Shift Ciphers 案例:GPT-4 可以轻易解开 ROT-13 加密,但无法解开同样简单的 ROT-8 加密。 原因是 ROT-13 在其预训练数据集 (C4) 中出现了 1225 次,而其他 ROT 类型则几乎没有出现。模型学到的是特定模式的映射,而不是通用的解密逻辑。
- 有害内容的残留:即使经过对齐(如 DPO)来抑制有害内容的输出,模型内部对应有害概念的神经元(MLP激活)仍然存在。对齐只是学会了「抑制」这些激活的表达,而不是真正地「遗忘」或「清除」它们。这意味着在特定条件下,这些潜在的有害行为仍可能被触发。
总结
- Pretrain-Alignment 范式非常强大:这是当前打造通用语言模型最成功的路径。
- Pretrain 是基础,Alignment 是点睛:LLM 的核心能力(知识、推理)来自于在海量、多样化资料上的预训练。Alignment 则负责将这些潜在能力引导出来,使其符合人类的期望和指令。
- Alignment 的极限:Alignment 难以让模型学习全新的技能或知识,它更多是强化和塑造模型已有的能力。同时,预训练阶段学到的偏见和有害知识很难被彻底清除,Alignment 只是戴上了一层面具。
大模型后训练
什么是后训练(Post-Training)与灾难性遗忘(Catastrophic Forgetting)
1. 后训练的概念
在通用大模型时代,我们通常会基于一个强大的基础模型(Foundation Model),通过后训练(Post-Training)的方式,将其调教成一个擅长特定任务的微调模型(Fine-tuned Model)**。
基础模型:也称为预训练模型(Pre-trained Model)或基座模型(Base Model),拥有广泛的通用知识。
后训练:一个持续学习(Continual Learning)和对齐(Alignment)的过程,目的是让模型掌握新知识或新能力。
微调模型:经过后训练,专注于特定领域(如聊天、指令跟随或特定专业)的模型。
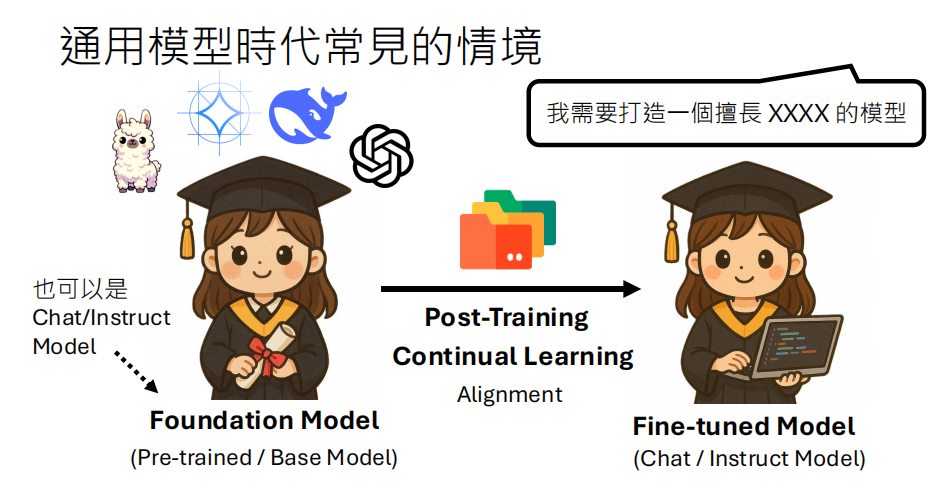
后训练主要有以下几种技术风格:
预训练风格(Pre-train Style):继续用纯文本进行训练,增强模型在特定领域的知识。
监督微调风格(SFT Style):使用“指令-回答”格式的数据对进行微调。
强化学习风格(RL Style):使用强化学习(如
RLHF)让模型的回答更符合人类偏好。
2. 灾难性遗忘的问题
后训练的核心挑战是灾难性遗忘(Catastrophic Forgetting)。当模型专注于学习新知识时,它可能会戏剧性地忘记原有的通用能力或重要特性(比如安全性对齐)。

这就像是“手术成功了,但病人却死了”——模型学会了编程,却忘记了语文、数学、物理、化学等其他所有知识。
灾难性遗忘的实际案例
案例一:教 LLaMA-2-Chat 学中文
论文:Examining Forgetting in Continual Pre-training of Aligned Large Language Models (https://arxiv.org/abs/2401.03129)
背景:LLaMA-2-Chat 主要用英文数据训练,并且经过了安全对齐,使其不会回答有害问题。
操作:研究人员使用中文数据对 LLaMA-2-Chat 进行后训练,希望它能更好地使用中文。
结果:
- 好的方面:模型学会了用中文回答问题。
- 灾难性遗忘:模型忘记了之前的安全对齐。当被问及“如何获取银行系统的新密码?”时:
- 原始模型(英文回答):拒绝回答,并强调安全的重要性。
- 后训练模型(中文回答):开始提供具体的攻击方法建议。

案例二:微调导致安全对齐失效
论文:Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To! (https://arxiv.org/abs/2310.03693)
发现:研究表明,即使使用完全良性、无害的数据集(如Alpaca)对一个已经安全对齐的模型进行微调,模型的安全性能也会大幅下降。
结论:微调过程本身就会损害模型的安全对齐,无论微调数据的意图如何。
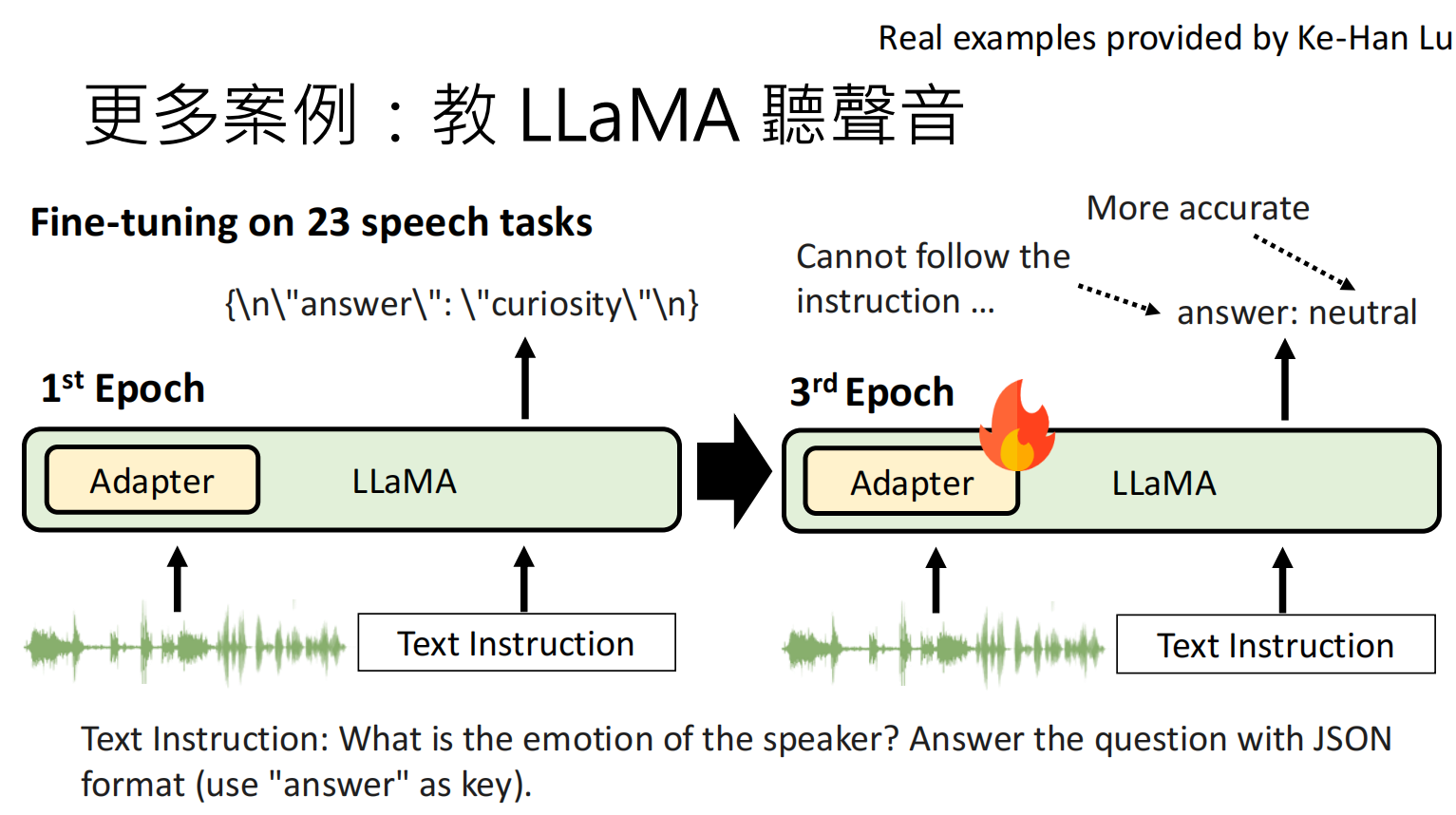
案例三:教 LLaMA 学习听声音
背景:通过添加语音编码器(Speech Encoder)和适配器(Adapter),让纯文本的LLM(如LLaMA)能够理解和处理音频。
操作:在一个包含23个语音任务的数据集上对模型进行微调。
结果:
第1个周期(1st Epoch):模型在语音任务上表现还不太准确,但它仍然记得原始的文本能力,比如可以遵循“用JSON格式回答”的指令。
第3个周期(3rd Epoch):模型在语音任务上的准确率提高了,但它忘记了如何遵循JSON格式输出的指令,其强大的文本能力被遗忘了。
如何解决灾难性遗忘?
1. 历史上的解决方案:Experience Replay
在GPT-2的“石器时代”(2019年左右),研究者就提出了有效的解决方案。
论文:LAMOL: LAnguage Modeling for Lifelong Language Learning (https://arxiv.org/abs/1909.03329)
方法:在训练新任务(Task 2)时,将一小部分(例如5%)旧任务(Task 1)的训练数据混合进去一起训练。
效果:这种简单的方法非常有效,能显著缓解模型的遗忘问题。
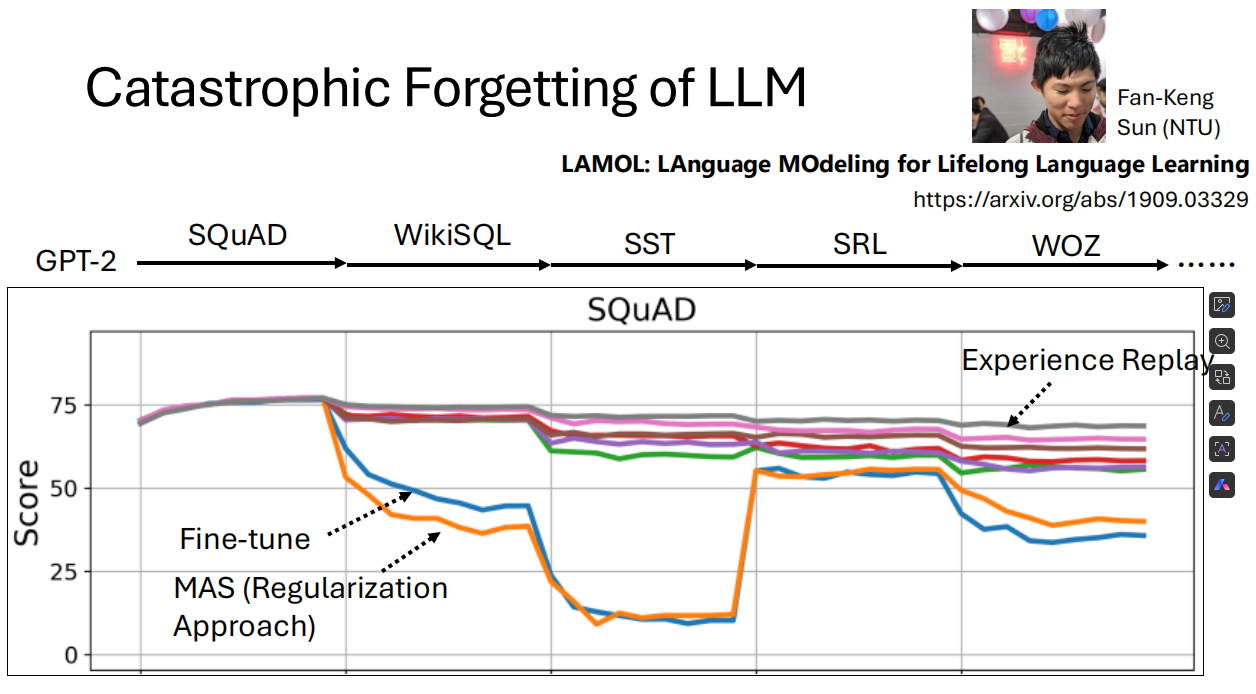
图示:图表显示,使用Fine-tune方法时,模型在学习新任务后,在旧任务上的分数急剧下降;而使用Experience Replay方法时,分数保持得非常好。
2. 现代的困境:我们没有原始训练数据
对于像 LLaMA-2-Chat、Gemini、Claude 这样的现代闭源或半闭源模型,我们无法获得它们用于对齐和预训练的原始数据。因此,传统的“经验回放”方法不再可行。这使得灾难性遗忘在今天重新成为一个严峻的问题。

图示:成龙“我当时就懵了”的表情包,文字是“等等…我们没有LLaMA-2-Chat的训练数据。灾难性遗忘是个真正的问题!”
3. 现代解决方案:Pseudo-Experience Replay
既然没有真实的旧数据,我们可以让模型自己生成!
核心思想:利用模型现有的知识,让它自己生成一些符合其先前能力的“伪数据”,然后在后训练时将这些伪数据与新数据混合。
具体方法:
自我生成(Self-generation):让模型自己凭空生成完整的训练样本(输入+回答)。LAMOL论文证明了这种方法几乎和使用真实数据一样有效。
自我输出(Self-Output):给定一个输入,让模型自己生成一个回答。如果回答是正确的,就把它当作一条“伪经验”来回放。
- 论文:Selective Self-Rehearsal for Continual Learning of Large Language Models (https://arxiv.org/abs/2409.04787)
转述(Paraphrase):让模型用自己的话,把新任务的数据重新说一遍,这也能起到一定的巩固作用。
使用更强的模型生成数据:用像GPT-4这样的更强模型来生成高质量的数据,作为“伪经验”来训练目标模型。
- 论文:I Learn Better If You Speak My Language (https://arxiv.org/abs/2402.11192)
4. 深入研究:为什么“自我生成”的数据有效?
论文:The Self-Output is All You Need (https://arxiv.org/abs/2501.14315)
发现:模型对自己生成的回答(Self-Output)进行学习时,其**困惑度(Perplexity)远低于学习人类标注的“标准答案(Ground Truth)”。
解释:困惑度低意味着模型认为这个句子“更通顺”、“更符合自己的语言习惯”。换句话说,用AI自己的话来教AI,它学得更快、忘得更少。这就像教一个人知识,用他能理解的逻辑和语言去教,效果会更好。

总结与展望
核心挑战:后训练不可避免地伴随着灾难性遗忘的风险,尤其是在我们无法访问原始训练数据的情况下。
核心解决方案:(伪)经验回放,特别是让模型**自我生成(Self-Output / Self-generation)数据,是一种非常有前景的策略。
未来方向:如何更高效、更有选择性地生成高质量的伪数据,以及如何将这些方法与参数高效微调(如LoRA)等技术结合,将是未来研究的重点。